Напрямую в запрос данные пользователя передавать нельзя!Это опасно. Пользователь может туда вставить любое sql выражение какое ему вздумается.
Это называется sql инъекцией. И в результате может, например, что-то изменить в базе или своровать данные.
PreparedStatement – как Statement, только безопаснее. Он добавляет методы для управления входными параметрами от пользователя.
Продемонстрируем пример SQL инъекции.
Пример программы:
import java.sql.*;
public class PrStatement {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement = connection.createStatement();
//Положим переменная ниже это данные от
//пользователя например которые он ввел
//в текстовое поле на странице и которые
//в результате пришли сюда в программу.
//Эта переменная будет передаваться в sql запрос.
String userInpData = “‘LOTR’ or name=’Book1′;”;
//Ниже в запрос передается переменная userInpData
ResultSet resultSet = statement.executeQuery(
“SELECT * FROM books where name=”+ userInpData);
//вредный вариант очевидно не безопасен.
//Так как пользователь прислал сюда не просто
//название книги, например LOTR, а целую часть
//SQL запроса и в итоге то что прислал
//пользователь сложиться с тем что в методе
//executeQuery и выполниться запрос:
//SELECT * FROM books where name=’LOTR’ or name=’Book1′;.
//который выведет две книги, а не одну как было
//по задумке программистом.
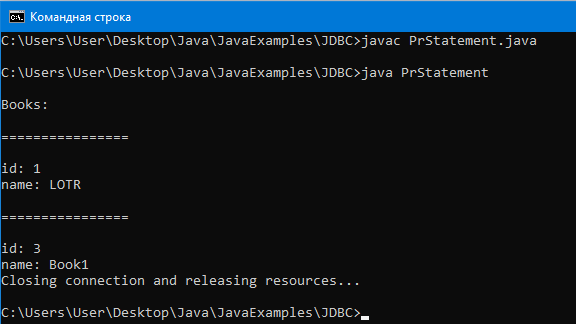
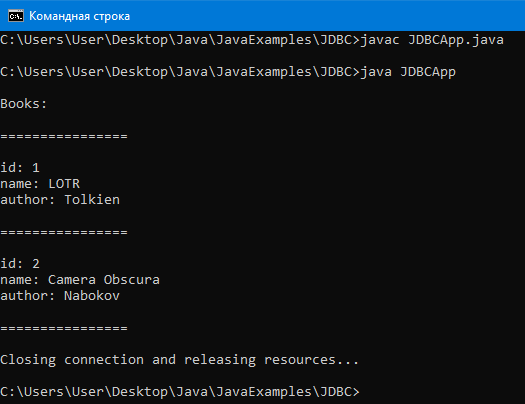
System.out.println(“\nBooks:”);
while (resultSet.next()) {
int id = resultSet.getInt(“id”);
String name = resultSet.getString(“name”);
System.out.println(“\n================\n”);
System.out.println(“id: ” + id);
System.out.println(“name: ” + name);
}
System.out.println(“Closing connection and ”
+”releasing resources…”);
resultSet.close();
statement.close();
connection.close();
}
}
Вывод:
Видим, что произошла инъекция SQL запроса пользователем в SQL запрос, который в методе executeQuery. Таким образом, вывелось две книги вместо одной, как задумывал программист.
Теперь продемонстрируем пример с PreparedStatement, которыйпредотвращает SQL инъекции.
Пример программы:
import java.sql.*;
public class PrStatement {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection = DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
String userInpData = “‘LOTR’ or name=’Book1′;”
//Запрос теперь делаем с помощью PreparedStatement
PreparedStatement pstatement =
connection.prepareStatement(
“SELECT * FROM books where name = ?”);
//В строке кода ниже первый параметр
//это порядковый номер вопросика
//в верхнем запросе, второй данные от пользователя,
//которые средствами PreparedStatement будут
//переданы в запрос на место этого вопросика
//уже безопасным образом.
pstatement.setString(1,userInpData);
//preparedstatement защищает нас от инъекций как
//бы пользователь не менял userInpData.
ResultSet presultSet = pstatement.executeQuery();
System.out.println(“\nBooks:”);
while (presultSet.next()) {
int id = presultSet.getInt(“id”);
String name = presultSet.getString(“name”);
System.out.println(“\n--------------------”);
System.out.println(“id: ” + id);
System.out.println(“name: ” + name);
}
System.out.println(“Closing connection and ”
+”releasing resources…”);
presultSet.close();
pstatement.close();
connection.close();
}
}
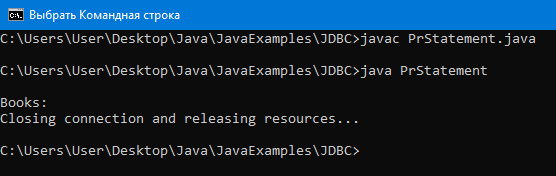
Вывод:
Видим, что ничего не вывелось, то есть PreparedStatement предотвратил инъекцию.
Фантомное чтение – по сути то же самое, что и неповторяющееся, только вместо update базы, будет insert в базу.
Для того чтобы изолировать транзакции от фантомного чтения, нужно в обеих вызватьTRANSACTION_SERIALIZABLE.
Пример программы:
import java.sql.*;
public class IsolationsPh {
public static void main(String[] args)
throws ClassNotFoundException,
SQLException, InterruptedException {
//здесь идет транзакция А
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement =
connection.createStatement();
connection.setAutoCommit(false);
connection.setTransactionIsolation(
Connection.TRANSACTION_SERIALIZABLE);
//Видим два селект запроса ниже
//между которыми перерыв 2 секунды.
ResultSet resultSet =
statement.executeQuery(“SELECT * FROM books”);
while (resultSet.next()) {
System.out.println(“name: ”
+ resultSet.getString(“name”));
}
//Запускаем поток транзакции В
//В нем транзакция В должна добавить новую
//книгу в БД пока транзакция А остановлена.
new TransactionB().start();
//на две секунды останавливаем
//поток транзакции А, то есть текущий.
Thread.sleep(2000);
//Поток транзакции В в данный момент
//заблокирован поскольку транзакция А еще
//не выполнилась полностью.
//И когда нижний селект выполниться поток
//транзакции В разблокируется и только
//тогда новые данные появятся в БД.
//То есть очевидно транзакции А и В
//не пересекаются и не мешают друг другу.
ResultSet resultSet1 =
statement.executeQuery(“SELECT * FROM books”);
while (resultSet1.next()) {
System.out.println(“name: ”
+ resultSet1.getString(“name”));
}
//В случае с фантомным чтением еще
//нужно закоммитить чтобы поток В
//разблокировался.
connection.commit();
}
static class TransactionB extends Thread {
@Override
public void run() {
try {
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement =
connection.createStatement();
connection.setAutoCommit(false);
connection.setTransactionIsolation(
Connection.TRANSACTION_SERIALIZABLE);
//Пока идут 2 секунды в течении которых
//поток транзакции А остановлен
//транзакция В должна добавить новую
//книгу в БД, но она этого не сделает
//поскольку установлен режим
//TRANSACTION_SERIALIZABLE который
//блокирует поток транзакции В пока
//полностью не выполнится транзакция А.
//Видим ниже insert, а не update.
statement.executeUpdate(“insert into ”
+”books (name, author) values ”
+”(‘new book’, ‘author of new book’)”);
connection.commit();
}
catch (SQLException e){}
}
}
}
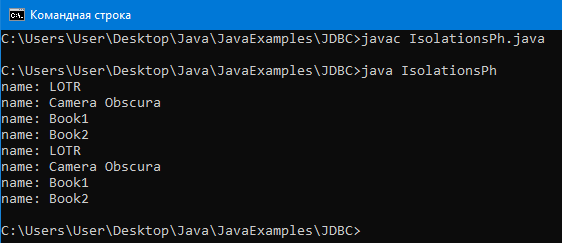
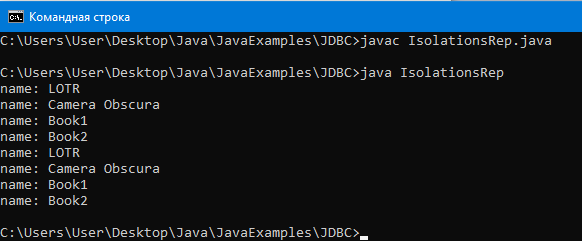
Скомпилируем, запустим программу:
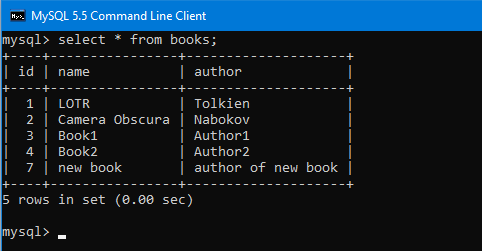
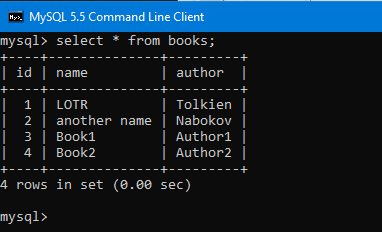
Проверим таблицу books после завершения работы программы через MySQL консоль:
Как видим, оба селекта считали из БД четыре записи, то есть, очевидно, ничего еще в БД транзакция В не успела добавить пока транзакция А не завершилась.
Допустим есть транзакция А и транзакция В в разных потоках.
Допустим в транзакции А есть несколько select запросов подряд.
Если транзакция В во время выполнения транзакции А изменит данные считываемые select-ами транзакции А, то это опять таки бывает не желательным.
Иногда нужно, чтобы сначала данные считались, то есть второй поток был заблокирован пока выполняется первый с транзакциейА, и данные обновились только после считывания всеми select-ами.
Для того чтобы изолировать транзакции от неповторяющегося чтения, нужно в обеих вызвать TRANSACTION_REPEATABLE_READ.
Пример программы:
import java.sql.*;
public class IsolationsRep {
public static void main(String[] args)
throws ClassNotFoundException,
SQLException, InterruptedException {
//здесь идет транзакция А
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “0799MSD”);
Statement statement = connection.createStatement();
connection.setAutoCommit(false);
//изолируем транзакцию от неповторяющегося чтения
connection.setTransactionIsolation(
Connection.TRANSACTION_REPEATABLE_READ);
//Выпим два селекта запроса ниже
//между которыми перерыв 2 секунды.
ResultSet resultSet =
statement.executeQuery(“SELECT * FROM books”);
while (resultSet.next()) {
System.out.println(“name: ”
+ resultSet.getString(“name”));
}
//Запускаем поток транзакции В
//В нем транзакция В должна менять данные
//второй книги пока транзакция А остановлена.
new TransactionB().start();
//на две секунды останавливаем
//поток транзакции А, то есть текущий.
Thread.sleep(2000);
//Поток транзакции В в данный момент
//заблокирован поскольку транзакция А еще
//не выполнилась полностью.
//И когда нижний селект выполнится поток
//транзакции В разблокируется и только
//тогда данные в БД изменятся им.
//То есть очередная транзакция А и В
//не пересекаются и не мешают друг другу.
ResultSet resultSet1 =
statement.executeQuery(“SELECT * FROM books”);
while (resultSet1.next()) {
System.out.println(“name: ”
+ resultSet1.getString(“name”));
}
}
static class TransactionB extends Thread {
@Override
public void run() {
//здесь идет транзакция В
try {
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement =
connection.createStatement();
connection.setAutoCommit(false);
connection.setTransactionIsolation(
Connection.TRANSACTION_REPEATABLE_READ);
//Пока идут 2 секунды в течении которых
//поток транзакции А остановлен
//транзакция В должна обновить данные
//второй книги, но она этого не сделает
//поскольку установлен режим
//TRANSACTION_REPEATABLE_READ, который
//блокирует поток транзакции В пока
//полностью не выполнится транзакция А.
statement.executeUpdate(“update books set”
+” name = ‘another name’ where id = 2″);
connection.commit();
}
catch (SQLException e){}
}
}
}
Скомпилируем, запустим программу:
Проверим таблицу books после завершения работы программы через MySQL консоль:
Как видим, оба селекта считали из БД одни и те же данные. То есть пока транзакция А не завершилась транзакция В не влияла на БД и соответственно на то, что считывала транзакция А.
Две или более выполняющиеся параллельно транзакции часто должны быть изолированы друг от друга.
Есть три случая когда необходимо изолировать транзакции друг от друга:
грязное чтение,
неповторяющееся чтение
фантомное чтение.
Начнем с грязного чтения.
В прошлых уроках о транзакциях мы говорили, что выполнение группы запросов, и соответственно изменение БД происходит только после вызова commit.
Но транзакции могут вести себя и по другому.
Например, можно сделать так, чтобы группа запросов даже до коммит производила изменения в БД, но если коммит так и не произошел, эти изменения откатятся. То есть коммит в этом случае просто делает так, чтобы изменения произведенные в базе там остались.
По умолчанию, как уже можно было понять, стоит первый вариант из двух приведенных. Он неявно установлен с помощью поляTRANSACTION_READ_COMMITTED.
Первый вариант исключает возможность грязного чтения. При втором же варианте возможно грязное чтение. Его уже нужно устанавливать явно с помощью поля TRANSACTIONS_READ_UNCOMMITED.
Грязное чтение
Допустим есть транзакция А и транзакция В, которые выполняются в разных потокахпараллельно при этом обе транзакции выполняются в режиме TRANSACTIONS_READ_UNCOMMITED,то есть грязное чтение возможно.
К транзакции А в потоке где она выполняется будет впоследствии применен rollback.
Значит данные в БД измененные транзакцией Ав конце концов окажутся недействительными,так как к ним будет применен rollback.
Но пока rollback не произошел к БД, которая была изменена транзакцией Амогут совершать запросы другие потоки, например, поток в котором выполняется транзакция В.
Очевидно, что если транзакция В обратиться к данным в БД, которые изменила транзакция А и которые в результате окажутся недействительными из-за примененного к этим данным rollback, это может быть очень нежелательным. То есть транзакция В будет работать с данными, которых в БД в результате не будет, так как к ним будет применен rollback.
Давайте уберем грязное чтение
Как уже говорилось, по умолчанию стоит TRANSACTION_READ_COMMITTED, поэтому грязного чтения не будет даже если не устанавливать TRANSACTION_READ_COMMITTEDявно.
Пример программы:
import java.sql.*;
public class IsolationsDirty {
public static void main(String[] args)
throws ClassNotFoundException,
SQLException, InterruptedException {
//здесь идет транзакция А
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement = connection.createStatement();
connection.setAutoCommit(false);
//установим режим транзакции при котором
//теперь невозможно грязное чтение.
//На самом деле TRANSACTION_READ_COMMITTED
//как уже говорилось установлен по умолчанию
//поэтому эту строчку кода можно не писать.
connection.setTransactionIsolation(
Connection.TRANSACTION_READ_COMMITTED);
//изменим имя второй книги в таблице
//Важно что теперь грязное чтение невозможно
//то есть запрос ниже выполнится только при следующем
//коммите. То есть транзакция В не будет читать
//данные, которые в итоге окажутся недействительными
statement.executeUpdate(“update books set name = ”
+”‘another name’ where id = 2″);
//Запускаем поток транзакции В
new TransactionB().start();
//при этом на две секунды останавливаем
//поток транзакции А, то есть текущий.
Thread.sleep(2000);
//После того как данные книг считаны
//транзакцией В, с помощью rollback делаем
//так чтобы изменения БД, которые должна сделать
//транзакция А при следующем коммите
//(то есть изменение второй книги) не случились.
connection.rollback();
}
static class TransactionB extends Thread {
@Override
public void run() {
//здесь идет транзакция В
try {
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement = connection.createStatement();
connection.setAutoCommit(false);
connection.setTransactionIsolation(
Connection.TRANSACTION_READ_COMMITTED);
//Пока транзакция А остановлена на 2 сек
//Извлекаем и выводим на консоль данные книг.
//В этом случае данные второй книги
//не изменены в БД транзакцией А.
//Так как чтобы они вступили в силу нужно
//чтобы случился коммит транзакции А.
ResultSet resultSet =
statement.executeQuery(“SELECT * FROM books”);
while (resultSet.next()) {
System.out.println(“name: ”
+ resultSet.getString(“name”));
}
} catch (SQLException e){}
}
}
}
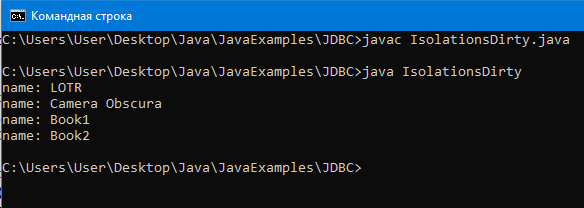
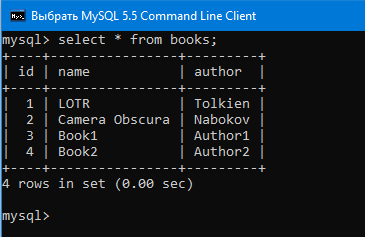
Скомпилируем, запустим программу:
Как видим, грязного чтения не произошло. Update запрос, который хотела выполнить транзакция А не был закоммичен, поэтому транзакция Вне читала никаких таких данных, которые в итоге оказались бы недействительными.
Класс SavePoint необходим для того, чтобы rollback был применен с определенной строки кода по определенную строку кода.
Пример программы:
import java.sql.*;
public class TransSaveP {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07031998MSD”);
Statement statement = connection.createStatement();
connection.setAutoCommit(false);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book1’, ‘Author1’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book2’, ‘Author2’);”);
Savepoint savep = connection.setSavepoint();
try {
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book3’, ‘Author3’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book4’, ‘Author4’);”);
//на запросе ниже случится ошибка и переход в catch
statement.executeUpdate(“INSERT INTO books (name,”
+”author) VALUES (‘Book5’, ‘Author5’, ‘str’);”);
connection.commit();
}
catch (SQLException e) {
//Отменяются только
//запросы выполненные после создания savep,
//запросы до него не будут отменены
connection.rollback(savep);
//То есть в данном примере будут отменены
//только третий и четвертый запрос.
//То есть те, которые до ошибки
//и которые после savep
//Чтобы выполнились команды
//до создания savep вызываем commit
connection.commit();
}
statement.close();
connection.close();
}
}
Скомпилируем, запустим программу и проверим таблицу books через MySQL консоль:
Видим, что случились только первый и второй запросы. То есть те, которые до savep. Всё после savep роллбекнулись.
Представим, есть некоторая последовательность SQL запросов, которые должны последовательно выполняться.
Если на определенном запросе возникнет ошибка, часто бывает, что необходимо откатить уже выполненные перед этим запросы.
Такое бывает необходимо когда набор последовательных SQL запросов связаны по смыслу, то есть без выполнения одного из запросов из этого набора нет смысла вы выполнении всех остальных. Очевидно, что если какой-то из запросов в наборе не выполнился, остальные, которые выполнились перед ним необходимо откатить. Набор связанных запросов называют транзакцией.
Управление транзакциями реализуется спец. методами класса Connection и доп. классом SavePoint
Пример программы:
import java.sql.*;
public class Transactions {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement = connection.createStatement();
//Строка кода ниже отменяет автоматическое выполнение
//каждой sql команды по отдельности. теперь они все
//будут выполнены только после вызова connection.commit()
connection.setAutoCommit(false);
try {
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book1’, ‘Author1’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book2’, ‘Author2’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book3’, ‘Author3’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book4’, ‘Author4’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book5’, ‘Author5’);”);
//если ошибок не возникало методом commit
//последовательно выполнятся все запросы выше
connection.commit();
}
catch (SQLException e) {
//Если возникла ошибка на каком-то из запросов выше
//то происходит переход сюда в catch
//метод commit при этом не произойдет так как мы видим
//выше что он после запросов).
//Метод rollback отменяет те запросы, в которых
//не было ошибок, которые были
//перед запросом, в котором ошибка произошла.
//Важно отметить что эти самые запросы, в которых не
//было ошибок еще не повлияли на БД, то есть они
//еще не случились, они случатся когда произойдет
//следующий commit.
//То есть например если в третьем
//по счету запросе произойдет ошибка и иза этого
//вызовется catch и перед rollback ниже мы вызовем
//метод commit то произойдет вставка в базу данных
//Book1 и Book2, то есть случатся первый
//и второй запрос и rollback уже ничего не сделает.
//Если же мы вызовем commit после rollback, а не перед
//ним то rollback отменит первый и второй запрос и
//они уже случатся при следующем commit то есть том,
//который после rollback так как rollback отменил их.
connection.rollback();
//Также важно заметить что
//отменяются только изменения UPDATE и INSERT
}
statement.close();
connection.close();
}
}
Скомпилируем, запустим программу и проверим таблицу books через MySQL консоль:
Видим, что в таблицу успешно добавились все запросы, так как в них не было ошибок.
Продемонстрируем те случаи, которые были описаны перед rollback в коде выше.
Для начала удалим те 5 книг, которые были добавлены в таблицу выше.
Теперь давайте сделаем так, чтобы в третьем запросе случилась ошибка и перед rollback сделаем commit.
Пример программы:
import java.sql.*;
public class Transactions {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
Statement statement = connection.createStatement();
connection.setAutoCommit(false);
try {
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book1’, ‘Author1’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book2’, ‘Author2’);”);
// на запросе ниже случится ошибка и переход в catch
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book3’, ‘Author3’, ‘str’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book4’, ‘Author4’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book5’, ‘Author5’);”);
connection.commit();
} catch (SQLException e) {
// коммитим первый и второй запрос
connection.commit();
// rollback уже ничего не сделает
connection.rollback();
}
statement.close();
connection.close();
}
}
Скомпилируем, запустим программу и проверим таблицу books через MySQL консоль:
Видим, что выполнился только первый и второй запрос.
Смысл транзакций теперь должен быть придельно понятен. Все запросы, в которых не было ошибок случаются с помощью commit, а rollback отменяет запросы, которые можно было бы закоммитить.
Давайте опять удалим те книги, которые были ранее добавлены в таблицу.
Теперь давайте сделаем так, чтобы в третьем запросе случилась ошибка и теперь сделаем сommit после rollback.
Пример программы:
import java.sql.*;
public class Transactions {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
Class.forName(“com.mysql.cj.jdbc.Driver”);
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “0799MSD”);
Statement statement = connection.createStatement();
connection.setAutoCommit(false);
try {
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book1’, ‘Author1’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book2’, ‘Author2’);”);
//на запросе ниже случится ошибка и переход в catch
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book3’, ‘Author3’, ‘str’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book4’, ‘Author4’);”);
statement.executeUpdate(“INSERT INTO books ”
+”(name,author) VALUES (‘Book5’, ‘Author5’);”);
connection.commit();
}
catch (SQLException e) {
//rollback отменит не два запроса которые
//могли бы случиться если бы мы вызвали
//commit перед rollback
connection.rollback();
//commit теперь ничего не сделает
connection.commit();
}
statement.close();
connection.close();
}
}
Скомпилируем, запустим программу и проверим таблицу books через MySQL консоль:
Видим, что в таблицу ничего не добавилось, так как rollback отменил те два запроса, которые можно было бы закоммитить.
JDBC – программный интерфейс для взаимодействия Java приложения и базы данных.
То есть, грубо говоря, мы можем работать с базой данных из Java программы.
В JDBC есть три основных класса для работы с базой:
Connection – для установки соединения с базой.
Statement – для выполнения sql запросов.
ResultSet – для получения результатов запроса.
Пример программы:
import java.sql.*;
public class JDBCApp {
public static void main(String[] args)
throws ClassNotFoundException, SQLException {
//В метод Class.forName нужно передать
//драйвер mysql благодаря которому DriverManager
//будет понимать что мы пытаемся подключиться
//именно к mysql базе так как базы бывают разные.
Class.forName(“com.mysql.cj.jdbc.Driver”);
//В метод getConnection передаем ссылку
//на базу, имя пользователя и пароль mysql
//таким образом устанавливается соединение
//текущей программы JDBCApp с базой данных
Connection connection =
DriverManager.getConnection(
“jdbc:mysql://localhost/storage”,
“root”, “07998MSD”);
//Чтобы передать запрос базе данных нужен
//объект statement, который возвращается из метода
//createStatement нашего соединения (connection)
Statement statement = connection.createStatement();
//executeUpdate – для обновления, создания
//или удаления чего в базе данных.
//Например создаем таблицу Books ниже.
statement.executeUpdate(“Create table Books ”
+”(id middleint not null auto_increment, ”
+”name VARCHAR(30) not null, ”
+”author VARCHAR(30) not null, PRIMARY KEY (id));”);
//И добавим пару книг в таблицу
statement.executeUpdate(“INSERT INTO Books ”
+”(name, author) VALUES (‘LOTR’, ”
+”‘Tolkien’);”);
statement.executeUpdate(“INSERT INTO Books ”
+”(name, author) VALUES (‘Camera Obscura’, ”
+”‘Nabokov’);”);
//далее можем передавать запрос
//через метод executeQuery, который возвращает
//объект ResultSet, который
//содержит результат запроса
ResultSet resultSet = statement.executeQuery(
“SELECT * FROM Books”);
System.out.println(“\nBooks:”);
//То есть как видим мы просто работаем с базой
//теми же самыми SQL запросами, которыми мы
//пользовались и раньше, но теперь через
//Java программу.
//next проходит по строкам таблицы базы данных
while (resultSet.next()) {
//в метод getType передаем номер атрибута
//или имя атрибута строки таблицы
int id = resultSet.getInt(“id”);
String name = resultSet.getString(“name”);
String author = resultSet.getString(“author”);
System.out.println(“\n====================\n”);
System.out.println(“id: ” + id);
System.out.println(“name: ” + name);
System.out.println(“author: ” + author);
}
System.out.println(“\n====================\n”);
System.out.println(“Closing connection and ”
+ “releasing resources…”);
resultSet.close();
statement.close();
connection.close();
}
}
Вывод:
Видим на консоли добавленные нами книги в базу данных.
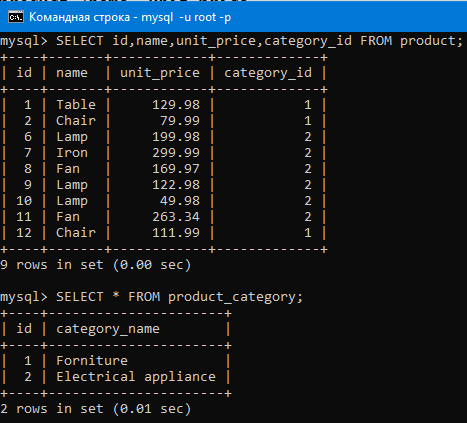
Как видим каждый продукт связан с категорией по внешнему ключу category_id. В category_id, как мы помним, находятся ключи из таблицы с категориями и таким образом таблицы связаны.
Так вот с помощью JOIN мы можем объединить эти две таблицы так чтобы в таблице с продуктами на место ключа в category_id становилась строка из таблицы с категориями соответствующая этому ключу.
И теперь из этой объединенной таблицы мы можем одновременно вывести аттрибуты из таблицы с продуктами и аттрибуты из таблицы с категориями.
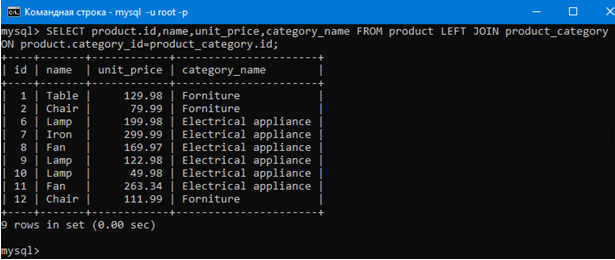
Сделаем это запросом:
SELECT product.id,name,unit_price,category_name FROM product LEFT JOIN product_category ON product.category_id=product_category.id;
Очевидно, что JOIN очень мощная штука, так как можно работать с двумя таблицами как с одной.
JOINможет дальше содержать и все другие ключевые слова типа where, group by и having.
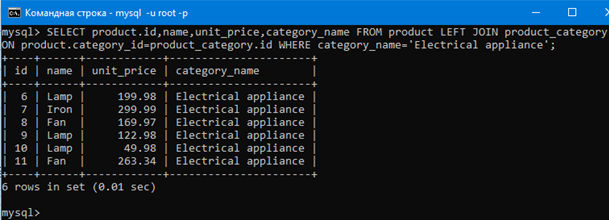
Например выведем только электроприборы sql командой:
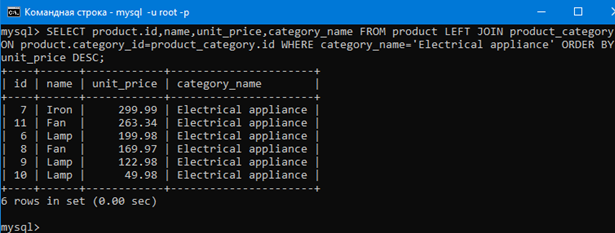
SELECT product.id,name,unit_price,category_name FROM product LEFT JOIN product_category ON product.category_id=product_category.id WHERE category_name=’Electrical appliance’;
Видим, что мы применили WHERE к объединенной таблице и получили из нее только электроприборы.
И еше остался вопрос. Почему LEFT?
left означает, что мы объединяем именно левую таблицу с правой. Левая это та, которая стоит слева от LEFT JOIN, а правая, которая справа от LEFT JOIN.
Почему это так важно, что именно левую с правой? А то, что в результирующей объединенной таблице строки из левой таблицы будут обязательно все до последней, а из правой только те строки, которым нашлась пара в левой таблице.
Можно вместо left поставить right, тогда объединяем правую с левой и всё будет наоборот.
Также можно вообще без left и Right. Это называется Inner Join. Тогда в результирующей объединенной таблице будут только те строки из обеих таблиц, у которых есть пара. То есть если какой-то из строк в первой талице нет пары в другой или какой-то из строк во второй таблице нет пары в первой, то они в результирующую таблицу не попадут.
Также результат какого-либо запроса можно отсортировать с помощью ORDER BY.
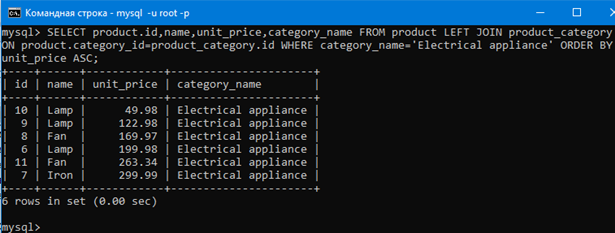
Например давайте отсортируем строки результата запроса ниже так чтобы они располагались в порядке уменьшения цены товара.
SELECT product.id,name,unit_price,category_name FROM product LEFT JOIN product_category ON product.category_id=product_category.id WHERE category_name=’Electrical appliance’;
Как видим, цена уменьшается сверху вниз. То есть сортировка строк происходит. DESC в конце значит от большего к меньшему.
Все. Самое главное по SQL разобрали.
Также еще нужно знать, что такое хранимые процедуры и транзакции, но их мы разберем когда будем учить JDBC и Hibernate
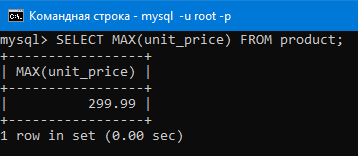
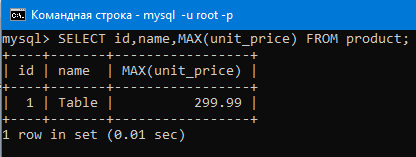
Теперь перейдем к подзапросам. Вот мы например вывели максимальное число в столбце.
Оно ясное дело тоже было в какой-то строке таблицы (строка с id 7 как можно увидеть ниже).
Как же нам вывести всю строку этого максимального числа (то есть мы хотим получить всю строку с id 7)?
Если мы сделаем так:
SELECT id,name,MAX(unit_price) FROM product;
То как видим, получаем не то, что нам нужно. id и name это значения из первой строки, а нам нужны те которые находятся в той же строке где находиться максимальное значение.
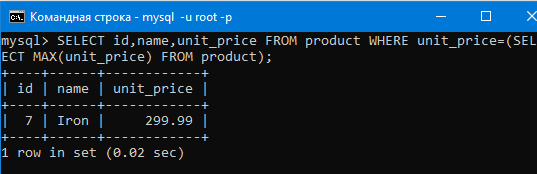
Чтобы всё получилось нужно использовать подзапрос.
Давайте выполним команду.
Первым SELECT-ом выбираются аттрибуты id,name,unit_price и из них выбирается только та строка где unit_price равное результату подзапроса(то есть второго SELECT, который в скобочках), а результатом подзапроса у нас будет максимальное значение в столбце unit_price.
То есть, как мы и хотели, вывело строку таблицы, в которой значение цены максимально. Вот так можно использовать подзапросы.
Далее разберем ключевое слово Group by и having. С помощью Group by можно разбить значения какого-либо выбираемого из таблицы аттрибута на группы.
Группы формируются так, что в каждую из них попадают строки с одинаковыми значениями указанного атрибута. То есть:
в одной группе — все строки с одним значением,
в другой — строки с другим значением,
в третьей — с ещё одним, и так далее.
На примере это будет гораздо понятнее 😉
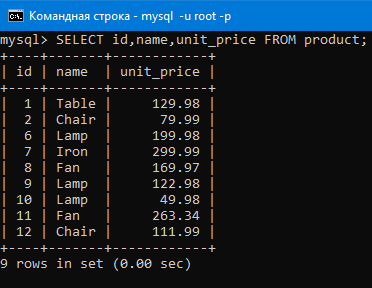
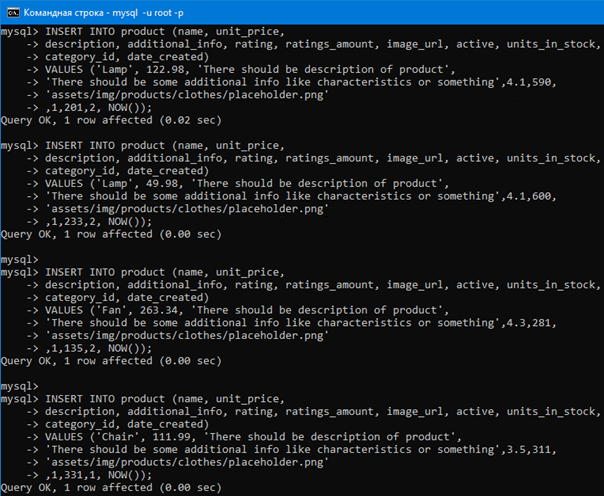
Для примера добавим в таблицу продукты из прошлых уроков еще пару ламп, еще один вентилятор и еще один стул. Это другие продукты, не те что были раньше, то есть у них будут другая цена, другое количество на складе и т.д. Ниже на картинке добавляем их (поскольку lamp, chair и др. будет повторяться несколько роз, можно представить, что мы добавили другие модели этих продуктов, хотя имя в таблице то же самое).
Добавили.
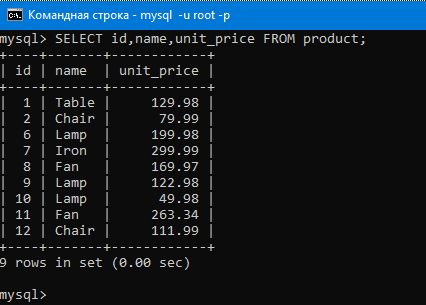
Теперь, что будет если мы совершим группировку по имени (вот так GROUP BY(name)).
Как уже было сказано, GROUP BY засовывает в одну группу одинаковые значения столбца. Групп в итоге будет пять, так как у нас пять разных значений в столбце name.
То есть в первой группе будут три лампы, во второй два вентилятора, в третьей два стула, в четвертой один стол, в пятой один утюг. И самое интересное, что к каждой из этих групп мы можем применить какую-нибудь агрегатную функцию.
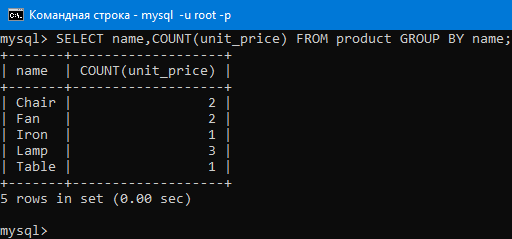
Давайте сгруппируем по имени и найдем количество продуктов в каждой группе командой:
SELECT name,COUNT(unit_price) FROM product GROUP BY name;
Как видим, результат соответствует тому, что было описано выше.
Запрос происходит в такой последовательности:
Сначала выбираются два столбца — name и unit_price. Потом строки группируются по значению name: все, где name = 'лампа', в одной группе, где name = 'вентилятор' — в другой и т.д. После этого для каждой группы считается, сколько в ней строк — с помощью COUNT(unit_price).
И теперь мы подошли к ключевому слову HAVING, которое используется ТОЛЬКО ЕСЛИ перед ним использовалось GROUP BY.
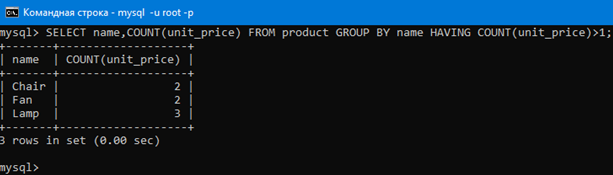
Представим, что над результатом того что получилось в результате предыдущей команды с GROUP BY нам нужно выполнить ЕЩЕ какие-то действия, то есть отфильтровать результат команды SELECT name,COUNT(unit_price) FROM product GROUP BY name; еще по какому-нибудь дополнительному условию.
Для этого применяется HAVING.
Для примера давайте выведем только те строки предыдущего результата, у которых COUNT(unit_price) больше 1. Это можно сделать запросом SELECT name,COUNT(unit_price) FROM product GROUP BY name HAVING COUNT(unit_price)>1;
Теперь вывелись только группы, в которых колличество строк больше 1.