Агрегатная функция может выполнить какие-либо операции над всеми значениями столбца или над группой значений этого столбца и как результат этих операций вернуть одиночное значение.
Например:
Можно сложить все значения числового столбца или сложить группу значений этого столбца с помощью функции SUM(), или вывести среднее арифметическое функцией AVG() или с помощью COUNT() посчитать количество строк в столбце, с помощью MIN() можно найти минимальное числовое значение в столбце, с помощью MAX() максимальное.
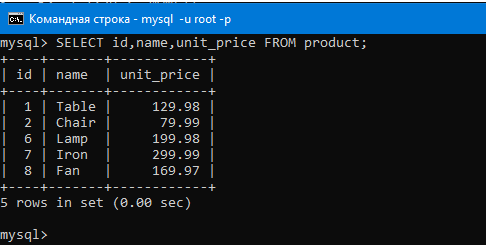
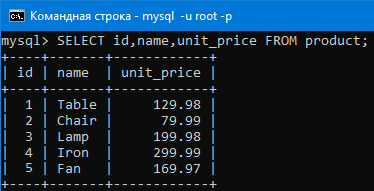
Посмотрим еще раз на таблицу перед вводом команды с функцией:
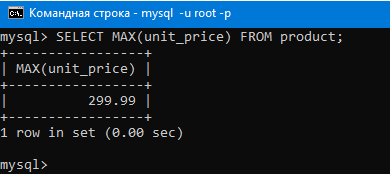
Теперь давайте выведем максимальное значение в столбце с ценой товара
Видим что вывело максимальное значение столбца, то есть 299.
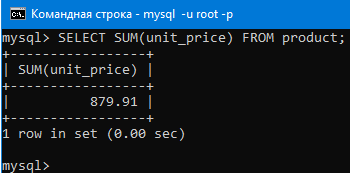
Можно вывести сумму всех значений в столбце с ценой.
Другие функциииспользуються подобным образом, разбирать их всех не будем.
В следующую группу команд под названием DML входят команды для манипулирования данными, а именно:
команда SELECTдля выборки данных из таблицы,
команда INSERTдля вставки данныхв таблицу,
команда DELETE для удаления строки таблицы
команда UPDATE для изменения строки таблицы.
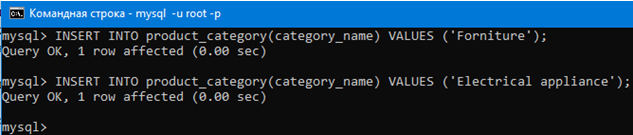
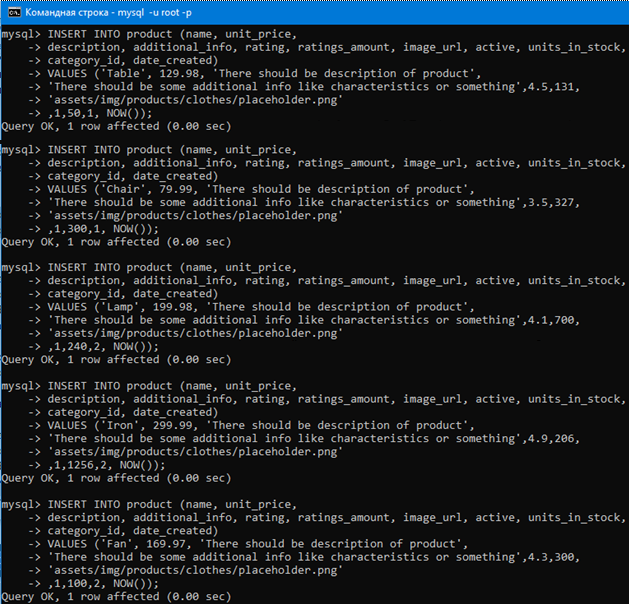
Воспользуемся такими insert запросами для добавления категорий в таблицу с категориями.
# INSERT INTO product_category – означает добавить
# в таблицу product_category.
# Далее в скобочках перечисляем аттрибуты,
# в которые мы собираемся
# добавить данные. В скобочках после VALUES
# указываем значения, которые будут
# вставляться в аттрибуты, которые мы
# указали в предыдущих скобках.
INSERT INTO product_category(category_name)
VALUES (‘Forniture’);
INSERT INTO product_category(category_name)
VALUES (‘Electrical appliance’);
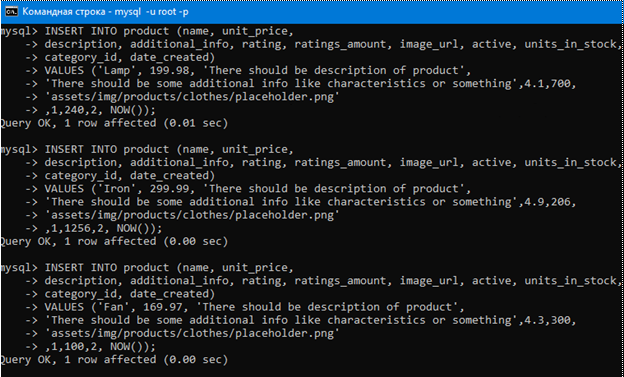
Воспользуемся такими insert запросами для добавления продуктов в таблицу с продуктами.
# Добавляем стол. Как видим здесь уже
# в скобках больше имен аттребутов
# и значений аттребутов чем в прошлых
# insert запросах. В таком случае
# вставка происходит так: ‘Table’
# вставляется в столбец name, 129.98
# в столбец unit_price, ‘There should
# be description of product’
# в столбец description и т.д. Думаю
# порядок добавления понятен.
INSERT INTO product (name, unit_price,
description, additional_info, rating,
ratings_amount, image_url, active,
units_in_stock, category_id, date_created)
# здесь видим что в аттребут
# category_id (то есть в столбец внешнего
# ключа) записано значение 1, что значит
# что стол (‘Table’) имеет
# категорию ‘Furniture’ (Мебель с англ.).
VALUES (‘Table’, 129.98, ‘There should be
description of product’, ‘There should be
some additional info like characteristics
or something’, 4.5, 131,
‘assets/img/products/clothes/placeholder.png’,
1, 50, 1, NOW());
# Подобным образом добавляем стул.
INSERT INTO product (name, unit_price,
description, additional_info, rating,
ratings_amount, image_url, active, units_in_stock,
category_id, date_created)
VALUES (‘Chair’, 79.99, ‘There should be
description of product’, ‘There should be some
additional info like characteristics or something’,
3.5, 327, ‘assets/img/products/clothes/placeholder.png’,
1, 300, 1, NOW());
# И т.д.
# Только здесь уже внешний ключ 2, так
# как лампа – это электроприбор.
INSERT INTO product (name, unit_price, description,
additional_info, rating, ratings_amount, image_url,
active, units_in_stock, category_id, date_created)
VALUES (‘Lamp’, 199.98, ‘There should be
description of product’, ‘There should be some
additional info like characteristics or something’,
4.1, 700, ‘assets/img/products/clothes/placeholder.png’,
1, 240, 2, NOW());
INSERT INTO product (name, unit_price, description,
additional_info, rating, ratings_amount, image_url,
active, units_in_stock, category_id, date_created)
VALUES (‘Toaster’, 299.99, ‘There should be description
of product’, ‘There should be some additional info
like characteristics or something’, 4.9, 206,
‘assets/img/products/clothes/placeholder.png’,
1, 1256, 2, NOW());
INSERT INTO product (name, unit_price, description,
additional_info, rating, ratings_amount, image_url,
active, units_in_stock, category_id, date_created)
VALUES (‘Fan’, 169.97, ‘There should be description
of product’, ‘There should be some additional info
like characteristics or something’, 4.3, 300,
‘assets/img/products/clothes/placeholder.png’,
1, 100, 2, NOW());
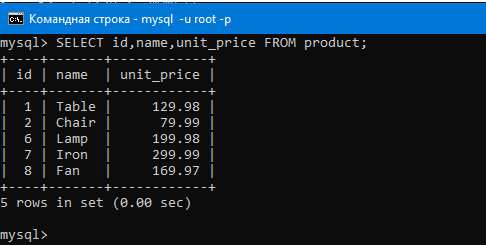
Давайте воспользуемся этими запросами.
Добавим категории в таблицу категорий.
Добавим продукты в таблицу с продуктами.
Теперь познакомимся с командой, которую вы будете чаще всего использовать.
Это команда SELECT для выборки данных из таблицы.
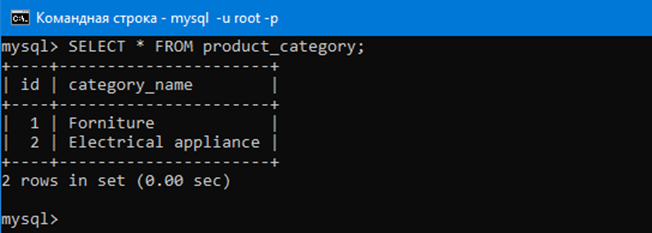
Выбирать все данные из таблицы с категориями можно с помощью запроса:
SELECT * FROM product_category;
После select указываются имена атрибутов данные, которых мы хотим выбрать из таблицы. В данном случае указана *, что значит что нужно выбрать данные вообще всех атрибутов в таблице.
После from указывается из какой таблицы мы собираемся выбирать данные аттрибутов. В данном случае из таблицы product_category.
Таким образом вбив данную команду в mysql консоли можно увидеть всё содержимое таблицы product_category.
Таким образом мы выбрали данные всех аттрибутов в таблице. Аттрибута там два – id и category_name.
Эти данные, как мы помним, мы туда ранее добавляли с помощью insert.
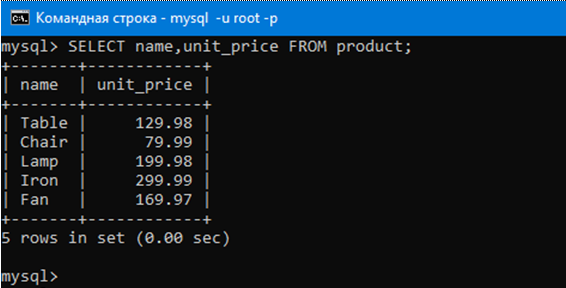
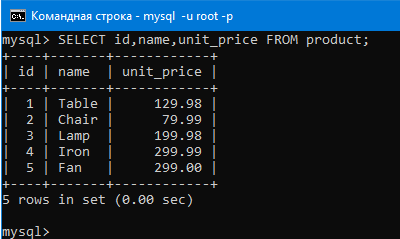
Теперь выберем столбцы name и unit_price из таблицы с продуктами запросом:
SELECT name,unit_price FROM product;
Видим, что мы выбрали этой командой только два аттрибута.
Как же нам теперь выбрать отдельную строку или несколько строк таблицы, а не все строки?
Для этого существует слово Where.
Приведем пример.
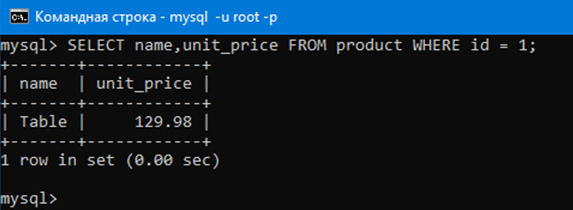
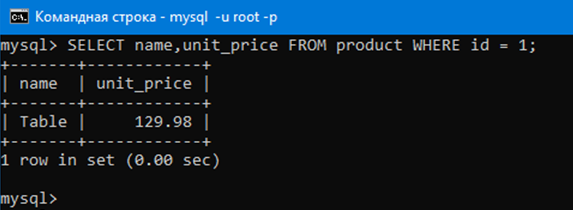
Перед этим мы выводили все строки аттрибутов name и unit_price.
Теперь выведем только те строки аттрибутов name и unit_price где в аттрибуте id стоит 1. Ясное дело это будет одна строка, так как мы извлекаем по ключу id.
Это можно сделать командой:
SELECT name,unit_price FROM product WHERE id = 1;
Как видим, мы получили одну строку. Эта строка, в которой ячейка аттрибута id равна единице. Давайте даже проверим это:
Действительно, как видим Table, 129,98 и 1 находятся в одной строке.
Словом SELECT мы задаем какие аттрибуты выбирать, а словом where какие строки. Точнее говоря словом Where мы задаем условие по которому происходит выборка строк.
Выберем теперь несколько строк и также выведем аттрибут id.
Как видим мы воспользовались ключевым логическим оператором or(или).
В условиях можно писать все стандартные логические операторы and, or или not.
А в данном случае мы запросили строки таблицы с продуктами где в ячейке аттрибута id находиться 2 или 4.
То есть мы достаем обе строки с помощью or, а не and, как на первый взгляд многим может показаться нужно делать.
Далее разберем ключевое слово Update. Оно нужно для обновления каких-либо строк таблицы по какому-то условию.
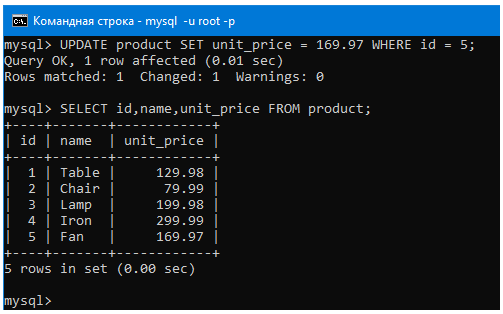
Например, изменим строку таблицы где ячейка аттрибута id = 5. Менять мы будем ячейку аттрибута цены продукта в этой строке.
Для этого воспользуемся запросом:
UPDATE product SET unit_price = 299 WHERE id = 5;
Посмотрим теперь содержимое таблицы после изменений:
Как мы помним, в строке где id был 5 цена была 169.97, теперь она изменилась на 299.
Вернем обратно с помощью запроса:
UPDATE product SET unit_price = 169.97 WHERE id = 5;
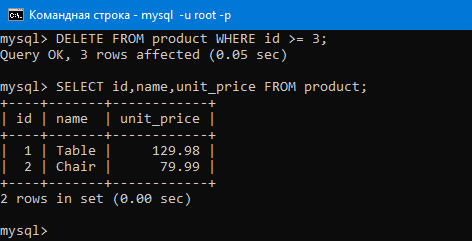
Далее разберем ключевое слово Delete. Оно нужно для удаления строк таблицы.
Например, удалим строки таблицы у которых id >= 3. То есть удалиться строка с id=3, строка с id=4 и строка с id=5.
Сделаем это с помощью запроса:
DELETE product WHERE id >= 3;.
Как видим, три последние строки таблицы удалились.
Командой create database создадим базу данных с именем ecommerce, то есть интернет магазин.
Перед прохождением раздела по SQL очень желательно пройти предыдущий раздел по базам данных чтобы всё было понятно 😉
Команды работы с БД делятся на группы. Рассмотрим группу DDL.
В нее входят команды определения структуры данных в БД. Точнее говоря команды для создания таблиц и удаления.
Создать таблицу можно командой create table, удалить – drop table.
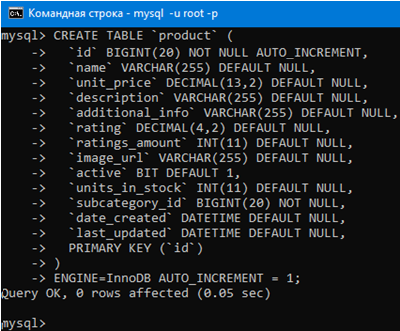
Запрос для создания таблицы с продуктами выглядит так:
# Комментарии в SQL это два прочерка “--” или “#”
# Создаем таблицу с именем products
CREATE TABLE `product` (
# Здесь в скобочках команды CREATE TABLE
# определяем атрибуты таблицы, в которые
# потом будем записывать данные.
# Добавляем атрибут `id`. В столбце этого
# атрибута будут храниться ключи продуктов.
# Ключи будут числового типа BIGINT.
# В скобках после типа всегда указывается
# количество символов. То есть максимум
# число может содержать 20 цифр.
# С помощью NOT NULL указываем, что столбец
# не может содержать пустых значений.
# С помощью AUTO_INCREMENT указываем, что
# при добавлении новой строки в таблицу
# не нужно будет вписывать значение в этот столбец вручную
# вместо этого будет автоматически увеличиваться
# последнее значение, которое присутствовало на единицу
# значение, которое присутствовало в этом
# столбце перед добавлением новой строки,
# и получившееся увеличенное значение будет
# ключом новой добавляемой строки.
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
# Добавим атрибут `name` – будут храниться
# наименования продуктов. VARCHAR значит, что
# этот атрибут будет хранить строковые
# значения.
`name` VARCHAR(255) DEFAULT NULL,
# цена продукта. DECIMAL – дробное значение
`unit_price` DECIMAL(13,2) DEFAULT NULL,
# и т.д.
`description` VARCHAR(255) DEFAULT NULL,
`additional_info` VARCHAR(255) DEFAULT NULL,
`rating` DECIMAL(4,2) DEFAULT NULL,
`listings_amount` INT(11) DEFAULT NULL,
`image_url` VARCHAR(255) DEFAULT NULL,
`is_active` BIT DEFAULT 1,
`units_in_stock` INT(11) DEFAULT NULL,
`date_created` DATETIME DEFAULT NULL,
`last_updated` DATETIME DEFAULT NULL,
# С помощью PRIMARY KEY указываем, какой
# атрибут будет ключом в таблице.
PRIMARY KEY (`id`)
)
ENGINE=InnoDB AUTO_INCREMENT = 1;
Теперь давайте используем этот запрос чтобы создать таблицу с продуктами.
Теперь удалим таблицу.
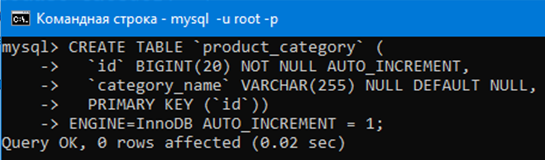
Давайте теперь сначала создадим таблицу с категориями продуктов, а потом таблицу продуктов чтобы потом соединить их связью Один ко Многим с помощью внешнего ключа.
Воспользуемся таким запросом для создания таблицы с категориями (здесь ничего нового):
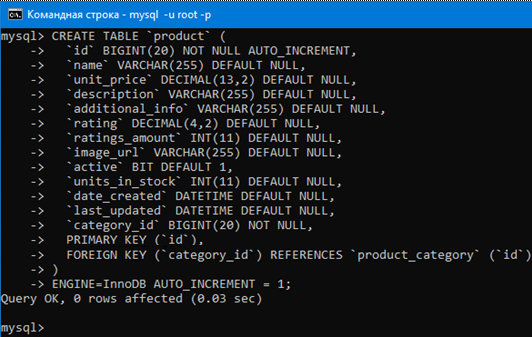
Теперь воспользуемся таким запросом чтобы опять создать таблицу с продуктами, но уже со столбцом внешнего ключа и конструкцией для связывания таблиц с его помощью.
CREATE TABLE `product` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`unit_price` DECIMAL(13,2) DEFAULT NULL,
`description` VARCHAR(255) DEFAULT NULL,
`additional_info` VARCHAR(255) DEFAULT NULL,
`rating` DECIMAL(4,2) DEFAULT NULL,
`ratings_amount` INT(11) DEFAULT NULL,
`image_url` VARCHAR(255) DEFAULT NULL,
`active` BIT DEFAULT 1,
`units_in_stock` INT(11) DEFAULT NULL,
`date_created` DATETIME DEFAULT NULL,
`last_updated` DATETIME DEFAULT NULL,
# Добавляем столбец внешнего ключа.
`category_id` BIGINT(20) NOT NULL,
# В category_id будут храниться ключи
# из таблицы с категориями.
# Таким образом мы связываем строки двух таблиц.
PRIMARY KEY (`id`),
# Связанный столбец `category_id` в этой таблице
# с ключом `id` из таблицы `product_category`
# с помощью конструкции FOREIGN KEY … REFERENCES …
FOREIGN KEY (`category_id`) REFERENCES `product_category` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT = 1;
Теперь мы можем вводить SQL команды для работы с СУБД.
Давайте воспользуемся этими запросами.
Создадим таблицу категорий.
Создадим таблицу продуктов, которая будет связана с таблицей категорий с помощью внешнего ключа.
Теперь при заполнении таблицы продуктов в столбец category_id нужно будет для каждого продукта писать ключ соответствующей ему категории из другой таблицы. Это увидим в следующем уроке.
Теперь разберемся как же работать с Базой Данных. То есть как создать таблицу, добавить в нее данные, извлечь из нее данные, удалить ееи т.д. Для этого используется язык запросов к БД – SQL.
Для начала нужно узнать где же хранить нашу базу данных, и через как с ней работать SQL запросами.
Для этого используется система управления базами данных (СУБД). Таких систем есть много – MySQL, Postgresql, MongoDB и другие.
Будем использовать MySQL, так как на ней принято учиться, хотя она используется не только для учебы, а и во вполне серьезных проектах.
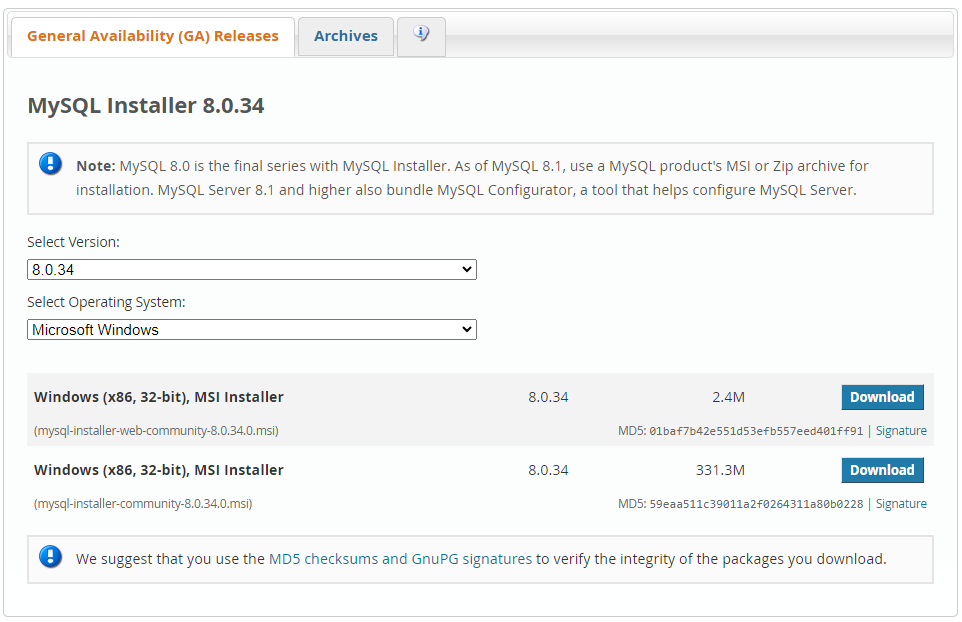
MySQL нужно скачать. Переходим по ссылке https://dev.mysql.com/downloads/installer/.
Нажимаем на второй Download, потом No thanks, just start my download. И происходит скачивание Mysql.
Открываем скачанный файл -> выбираем custom -> Далее везде next -> когда попросят создать пароль вы его создаете -> далее всё next.
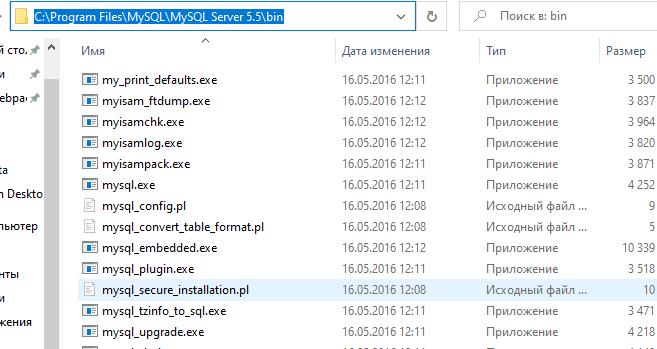
Далее переходим в папку C:\Program Files\MySQL. Переходим в папку bin и копируем путь C:\Program Files\MySQL\MySQL Server 5.5\bin.
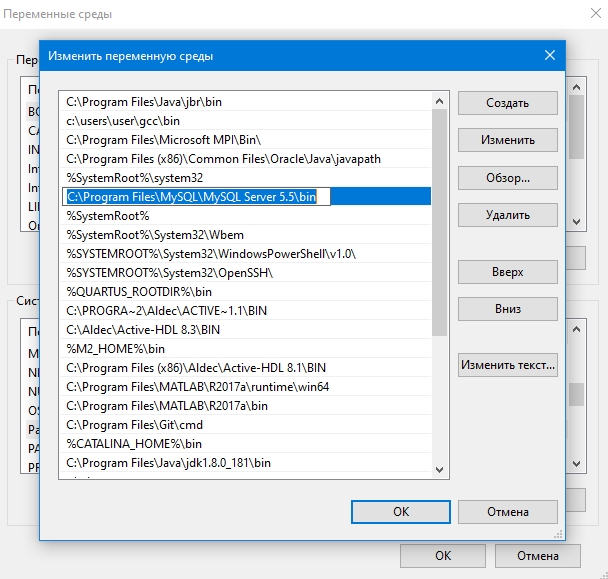
Переходим в изменение системных переменных также как мы добавляли javac ранее в самых первых уроках и добавляем в path только что скопированный путь C:\Program Files\MySQL\MySQL Server 5.5\bin.
Теперь через командную строку можем работать с СУБД.
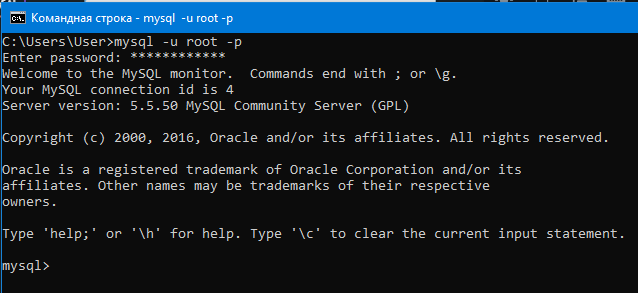
Переходим в режим работы с MySQL командой mysql -u root -p.
Теперь мы можем вводить SQL команды для работы с СУБД.
Как понятно из названия, каждой строке одной таблицы соответствует только одна строка в другой.
Почти не используется за редкими исключениями, так как очевидно, что соединение таблиц связанных таким образом в одну не приведет к дублированию данных.
Но бывают случаи когда это бывает полезно.
Самый полезный случай – это когда мы хотим отделить из основной таблицы данные, которые относятся только к ее части.
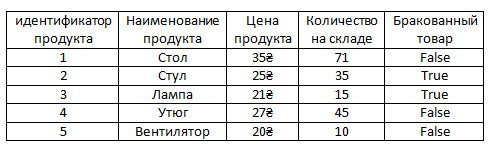
Например, есть наша основная таблица Продукты.
И пусть в ней будет новый аттрибут – Бракованный товар. То есть например, все лампы из тех, что есть на складе оказались бракованными или все стулья, которые есть на складе оказались бракованными. То есть представим, что эти все стулья и лампы это какая-то конкретная их модель и эта модель выпускалась с браком, такое бывает. Тогда у них в этом столбце будет стоять true, то есть бракованные, если всё в порядке то false.
Так вот, очевидно, что у большей части продуктов в таблице будет стоять false. Так как такой массовый брак какого-то продукта это скорее редкость.
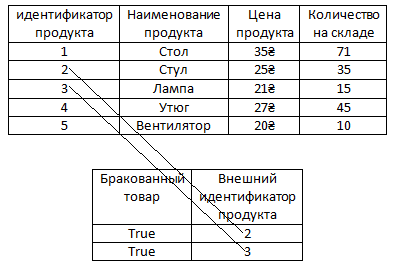
Для того чтобы нам не хранить информацию в таблице с продуктами о том, что с ними всё в порядке можно вынести информацию о том, что какие-то продукты бракованные в отдельную таблицу.
И ясное дело в этой новой таблице, как видим, намного меньше записей, чем если бы информация о браке хранилась в формате столбца в таблице с продуктами, так как уже было сказано в ней нет информации о том, что какие-то продукты не бракованные. То есть, как видим, в ней нету false, эту информацию в этой таблице хранить незачем, поскольку если у какого-то продукта нету связанной строки в таблице барка, это само по себе значит, что продукт не бракованный. То есть у стола, утюга и вентилятора нету связи с таблицей брака и это само по себе значит, что с этими продуктами всё в порядке.
Второй случай использования связи Один-к-одному – это если, например, в таблице слишком много столбцов, то чтобы ее немного уменьшить можно некоторые столбцы вынести в отдельные таблицы.
Третий случай – это когда у нас, например, есть таблица с продуктами и у продуктов появляется какой-то новый ВРЕМЕННЫЙ аттрибут. То есть мы точно знаем, что этот столбец мы со временем удалим из таблицы. И создавать новый столбец в основной таблице не всегда бывает удобно, легче создать отдельную таблицу чтобы потом с легкостью ее удалить.
Четвертый случай – это из соображений безопасности. То есть если злоумышленник получит доступ к основной таблице, а в ней есть какие-то очень секретные аттрибуты, то он может просто пройтись по строкам таблицы и выбрать эти все секретные данные. очевидно безопаснее было бы хранить эти секретные данные в виде отдельных таблиц чтобы хацкер не смог получить их всех скопом.
ВСё!! С информацией полученной в этом разделе курса вы сможете спроектировать реляционную БД любой сложности.
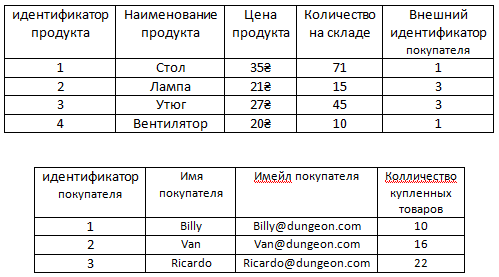
У каждого продукта есть много покупателей и у каждого покупателя есть много купленных продуктов.
Ясное дело должно быть две таблицы – Продукты и Покупатели продуктов. И как-то нужно их связать.
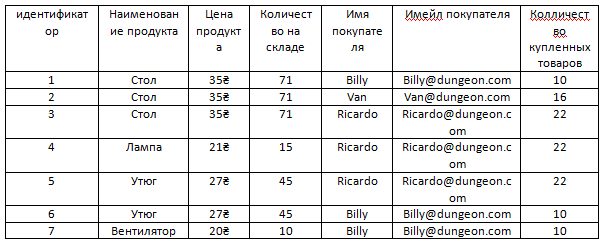
Но для начала следует увидеть одну таблицу, в которой хранятся данные обеих только что упомянутых таблиц вместе.
Очевидно, что аттрибуты Имя покупателя, Имейл покупателя и Количество купленных товаров принадлежат не таблице продукты и их нужно отделить в отдельную таблицу Покупатели продуктов.
Также, как можно увидеть, повторяются в этой таблице и продукты и покупатели.
Например, Ricardo купил стол, лампу и утюг, но стол также купили Billy и Van. То есть повторение идет и покупателей и продуктов.
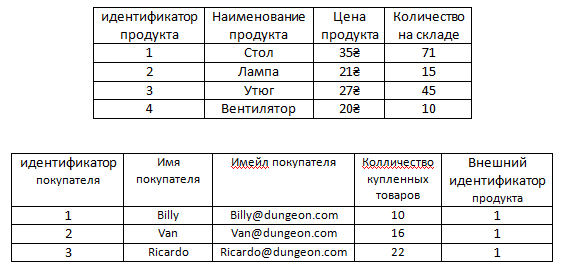
Поэтому таблицы нужно разделить и связать их связью многие-ко-многим.
Почему она многие-ко-многим думаю уже понятно – каждый покупатель может купить МНОГО разных продуктов и каждый продукт может быть куплен МНОГИМИ разными покупателями.
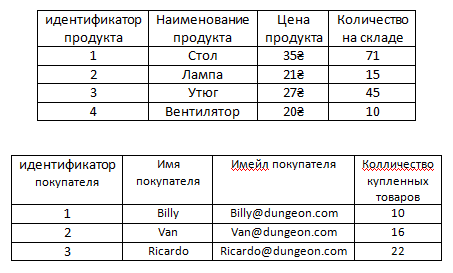
Итак разобьем же таблицу на две
Как же нам теперь связать эти две таблицы?
Итак подумаем. Что если, как мы уже делали ранее в таблице продукты, добавить аттрибут Внешний идентификатор покупателя, в котором для каждого продукта будут храниться нужные идентификаторы покупателя из таблицы с покупателями.
Но подождите! Если мы посмотрим на исходную таблицу (ту которая была в самом начале урока), то стол же купил не только Billy, его купил и Van и Ricardo. Утюг также купил Billy и Ricardo.
Получается, что в таблице Продукты на рисунке выше намнужно размножить стол и утюг. Так, ясное дело, нельзя, ведь нам же нужно минимизировать количество повторений данных в базе.
Давайте попробуем наоборот.
Очевидно та же самая ситуация. Только размноживать теперь придется покупателей.
Как же быть?
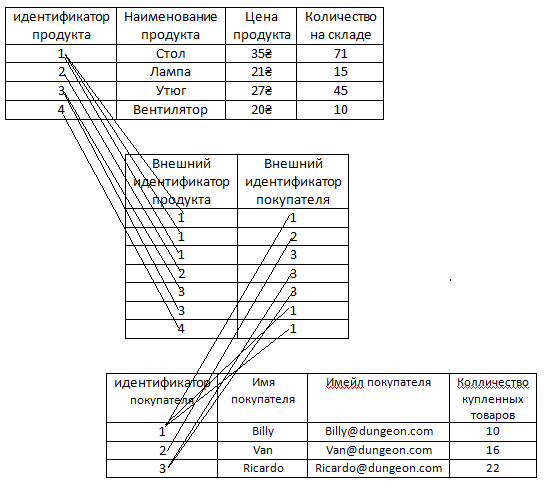
Нужно создать третью таблицу. В этой таблице будут всего два аттрибута – Внешний идентификатор продукта и Внешний идентификатор покупателя. То есть очевидно, что в этих аттрибутах будут храниться ключи из других таблиц. И эти ключи разных таблиц будут сопоставлены друг другу, таким образом образуя связь меду двумя таблицами.
Продемонстрируем это:
Как видим, в первом столбике ключи из таблицы продукты, во втором же ключи из таблицы покупатели.
Видим три единицы подряд в первом столбце.
Получается мы сопоставляем строку таблицы с продуктами где идентификатор 1 к строке покупателя с идентификатором 1, к строке покупателя с идентификатором 2 и к строке покупателя с идентификатором 3. То есть стол связан с Billy, Van и Ricardo.
Во втором столбце видим три тройки подряд.
То есть мы сопоставляем строку таблицы с покупателями где идентификатор 3 к строке продукта с идентификатором 1, к строке продукта с идентификатором 2 и к строке продукта с идентификатором 3. Ricardo связан со столом, лампой и утюгом.
Как видим, множественная связь работает в обе стороны. С одной стороны может быть много столов и с другой стороны может быть много Ricardo.
И нам не приходиться, как в исходной таблице (той которая на самой первой картинке урока), дублировать строки целиком из обеих таблиц. Строки двух таблиц связывает отдельная таблица, в которой всего два столбца с числовыми значениями.
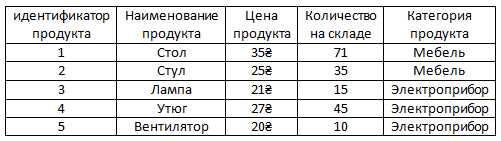
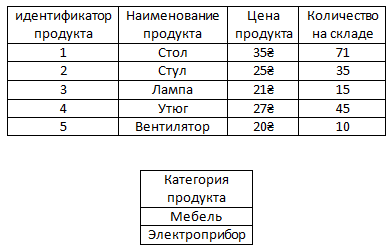
Есть таблица "Продукты". У каждого продукта может быть категория, к которой он принадлежит.
Например, стол и стул относятся к категории мебель, а лампа, утюг и вентилятор к категории электроприборы.
Давайте же добавим в таблицу из прошлого урока аттрибут "Категория продукта".
Как видим, слово Электроприбор повторяется три раза, слово мебель два раза.
А что если у нас в таблице будет больше электроприборов и больше мебели, то значит у нас в таблице будут повторяться эти два слова еще больше раз?
Именно поэтому добавлять такой аттрибут, значения которого повторяются много раз, нельзя, так как мы с вами сейчас изучаем реляционную модель базы данных, которая определяет некоторые правила создания БД чтобы в ней практически вообще не было повторяющейся информации.
Так как же нам поступить с новым добавленным аттрибутом чтобы не было повторяющейся информации?
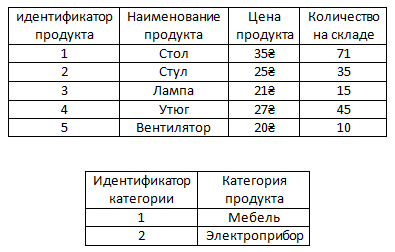
Всё просто, нужно его вынести в отдельную таблицуи в ней уже будут храниться уникальные значения, а потом получившиеся две таблицы связать между собой.
То есть мы сейчас подошли к двум новым концепциям – идентификаторам (чаще называют ключами) и связям.
Разбиваем таблицу. Вторая таблица будет иметь имя Категория продукта.
Как видим теперь информация не повторяется.
Теперь как же связать эти две таблицы?
Для этого используется идентификатор(ключ).
Что же такое идентификатор?
Например, в таблице Продукт можно увидеть аттрибут Идентификатор продукта.
Идентификатор в этой таблице идентифицирует продукт, по нему можно отличить один продукт от другого.
Соответственно идентификаторы у продуктов в таблице обязательно должны быть разными чтобы по идентификатору можно было обратиться к одному конкретному продукту.
Идентификаторы продуктов хранятся в отдельном столбце таблицы и ясное дело, как уже было сказано, в этом столбце не должно быть одинаковых значений.
Идентификатор чаще всего это простое числовое значение.
Таблице с категориями тоже добавим аттрибут Идентификатор категории, который будет хранить значения, которые однозначно идентифицируют ту или иную категорию.
Итак, теперь давайте уже непосредственно к тому как же связать таблицы.
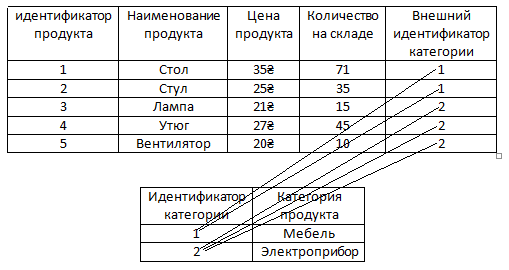
Для этого в таблице продукт нужно создать дополнительный столбец с внешним ключом, то есть ключ, который внешний, то есть из другой таблицы. Добавим этот столбец.
На картинке можно увидеть, что значения в столбце 'Внешний идентификатор категории'это значения из столбца 'Идентификатор категории' внешней таблицы категорий. То есть мы связали две таблицы по ключу в таблице с категориями.
И теперь нету дублирования Мебель или Электроприборы, дублируются только значения идентификаторов этих категорий.
Кто-то может спросить, а какая разница дублируются категории или идентификаторы?
Разница в том, что в таблице с категориями может быть не один аттрибут, а больше.
Например:
Если бы мы не разделяли таблицы, то дублировалось бы уже два аттрибута:
Теперь профит от разделения таблиц должен быть очевиден.
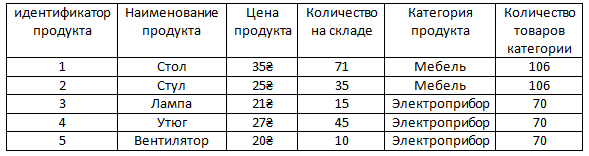
Рассмотренный тип связи называется 'Один-ко-многим'.
Всего типов связей три и мы всех их разберем.
Один ко многим эта связь, потому что каждому продукту может соответствовать только ОДНА категория, но каждой категории может соответствовать МНОГО продуктов.
То есть у нас категории мебель (она одна) соответствует два продукта (их много), а категории электроприборы (она одна) соответствует три продукта (их много).
Думаю можно догадаться, что это хранилище, в котором хранятся данные.
Наиболее удобный вариант хранения данных в БД в виде таблиц.
Конкретная таблица БД хранит в себе данные какой-либо конкретной сущности.
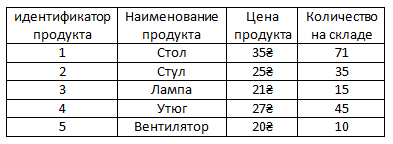
Например, есть таблица сущности 'Продукт'. В этой таблице могут храниться много разных продуктов (там например стол, стул, лампа и т.д.).
Каждая строка таблицы хранит характеристики конкретного продукта, то есть одного из этих многих продуктов.
То есть, например, одна строка таблицы хранит данные о лампе, другая о стуле и т.д.
Строки таблицы разбиты на ячейки.
В каждой ячейке строки храниться конкретная какая-либо характеристика конкретного продукта (например стула).
Как и в вообще почти любой на свете таблице, ячейки строки таблицы формируются по столбцам и у этих столбцов таблицы зачастую есть имена. Есть имена и у столбцов таблиц в БД.
Например имя продукта, цена продукта, количество на складе или другое. То есть названия характеристик продукта по которым определяется в какую ячейку строки конкретного продукта значение какой характеристики помещать.
Столбцы таблицы принято называть аттрибутами, а строки кортежами.
Сейчас на примере таблицы Продукт будет понятнее.
Видим аттрибуты продуктов таблицы (Идентификатор продукта, Наименование продукта, Цена продукта, Количество на складе).
Также видим пять кортежей (значит пять продуктов).
Если мы представим, что это таблица базы данных используется в реальном магазине, то ясное дело если какой-нибудь из товаров купят, то его количество в таблице должно уменьшиться, если цена на него уменьшиться, то тоже таблица должна быть отредактирована.
Редактирование таблицы совершается специальными командами о которых поговорим позже.
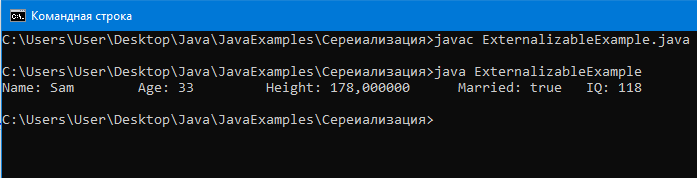
Представим, что нужно сериализовать объект созданного нами класса расширяющий вообще сторонний класс, который не Serializable, из вообще стороннего jar, который мы скачали откуда-то из интернета.
Ясное дело, поля стороннего класса не сериализуються и не десериализуються.
Externalizable поможет. Благодаря нему можно силой сериализовать и десериализовать поля стороннего класса реализовав методы writeExternal (для сер) и readExternal (для дес).
Пример программы:
import java.io.*;
public class ExternalizableExample {
public static void main(String[] args) {
// сериализуем
try(ObjectOutputStream oos =
new ObjectOutputStream(
new FileOutputStream(“person.dat”)))
{
Person p = new Person(“Sam”, 33, 178, true, 118);
oos.writeObject(p);
}
catch(Exception ex){
System.out.println(ex.getMessage());
}
// десериализация
try(ObjectInputStream ois =
new ObjectInputStream(
new FileInputStream(“person.dat”)))
{
Person p = (Person) ois.readObject();
System.out.printf(
“Name: %s \\t Age: %d \\t Height: %d \\t ” +
“Married: %b \\t IQ: %d \\n”,
p.getName(), p.getAge(), p.getHeight(),
p.getMarried(), p.getIQ());
}
catch(Exception ex){
System.out.println(ex.getMessage());
}
}
}
// представим что типа сторонний класс,
// который не реализует Serializable
// и нет никакой возможности
// сделать его Serializable
// но сериализовать его надо
class MyClass {
private boolean married;
private int IQ;
public MyClass() {}
public MyClass(boolean m, int iq) {
married = m; IQ = iq;
}
boolean getMarried() { return married; }
void setMarried(boolean married) {
this.married = married;
}
int getIQ() { return IQ; }
void setIQ(int IQ) { this.IQ = IQ; }
}
//вместо Serializable – Externalizable
class Person extends MyClass
implements Externalizable{
private String name;
private int age;
private double height;
public Person(){}
public Person(String n, int a, double h,
boolean m, int iq) {
super(m, iq);
name=n; age=a; height=h;
}
String getName() {return name;}
void setName(String name) {this.name = name;}
int getAge() {return age;}
void setAge(int age){this.age = age;}
double getHeight(){return height;}
void setHeight(double height){this.height=height;}
@Override
public void writeExternal(ObjectOutput out)
throws IOException {
//вручную передаем методом сериализации
//(методам writeUTF, writeInt, …)
//поля сериализуемого объекта, которые
//мы хотим сериализовать
out.writeUTF(getName());
out.writeInt(getAge());
out.writeDouble(getHeight());
//это поле из класса, который не Serializable
out.writeBoolean(getMarried());
//и это поле из класса, который не Serializable
out.writeInt(getIQ());
//Но теперь мы можем такие
//поля сериализовать
//вот так вручную так сказать.
//Правда вручную теперь также нужно
//сериализовать и поля класса Person,
//который должен был быть Serializable,
//но он Externalizable по понятным причинам.
}
@Override
public void readExternal(ObjectInput in)
throws IOException, ClassNotFoundException {
//здесь учитывая порядок предшествующей
//сериализации полей в методе выше
//десериализуем их методами десериализации
setName(in.readUTF());
setAge(in.readInt());
setHeight(in.readDouble());
setMarried(in.readBoolean());
setIQ(in.readInt());
}
}
Вывод:
Как видим, сериализуются все поля даже класса, который не Serializable.
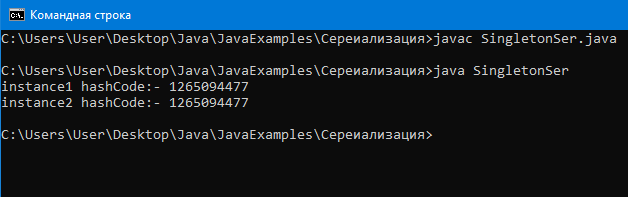
Cинглтон это класс, который может иметь только один экземпляр. То есть другой экземпляр этого класса невозможно создать.
Если мы сериализуем этот экземпляр, а потом десериализуем, то получим уже второй экземпляр синглтона, что противоречит идее синглтона.
Чтобы десериализовался тот же экземпляр нужно определить метод readResolve.
Пример программы:
import java.io.*;
//класс синглтон
class Singleton implements Serializable {
public static Singleton instance = new Singleton();
//приватный конструктор нужен
//чтобы невозможно было создавать
//объект данного класса вне класса Singleton.
//то есть выше мы создали один объект
//и больше ни одного создаваться не будет
private Singleton() {
}
// private constructor
//Все что нужно сделать это определить
//в классе синглтона метод с именем readResolve
//вот так как ниже и сериализоваться
//в итоге будет тот же объект синглтона
protected Object readResolve() {
return instance; } //возвращает этот же объект
}
public class SingletonSer {
public static void main(String[] args) {
try {
//снизу обычная сериализация.
//как в прошлых уроках
Singleton instance1 = Singleton.instance;
ObjectOutput out = new ObjectOutputStream(
new FileOutputStream(“file.text”));
out.writeObject(instance1);
out.close();
ObjectInput in = new ObjectInputStream(
new FileInputStream(“file.text”));
Singleton instance2
= (Singleton) in.readObject();
in.close();
//теперь instance1 и instance2 возвращают один
//и тот же hashCode что значит
//что это один и тот же экземпляр
System.out.println(“instance1 hashCode:- ”
+ instance1.hashCode());
System.out.println(“instance2 hashCode:- ”
+ instance2.hashCode());
}
catch (Exception e) {
e.printStackTrace();
}
}
}
Вывод:
Как видим, instance1 и instance2 возвращают один и тот же hashCode, что значит, что это один и тот же экземпляр, что значит, что концепция синглтона не нарушается.