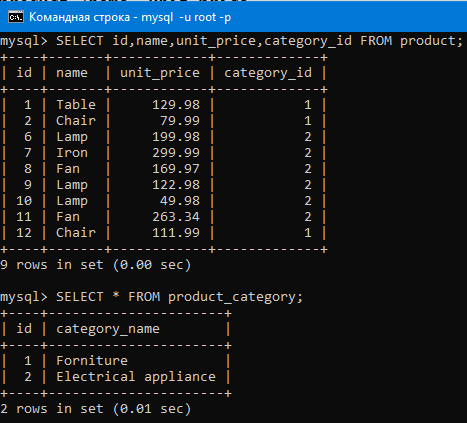
Как видим каждый продукт связан с категорией по внешнему ключу category_id. В category_id, как мы помним, находятся ключи из таблицы с категориями и таким образом таблицы связаны.
Так вот с помощью JOIN мы можем объединить эти две таблицы так чтобы в таблице с продуктами на место ключа в category_id становилась строка из таблицы с категориями соответствующая этому ключу.
И теперь из этой объединенной таблицы мы можем одновременно вывести аттрибуты из таблицы с продуктами и аттрибуты из таблицы с категориями.
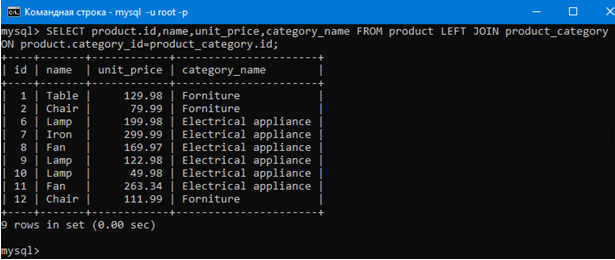
Сделаем это запросом:
SELECT product.id,name,unit_price,category_name FROM product LEFT JOIN product_category ON product.category_id=product_category.id;
Очевидно, что JOIN очень мощная штука, так как можно работать с двумя таблицами как с одной.
JOINможет дальше содержать и все другие ключевые слова типа where, group by и having.
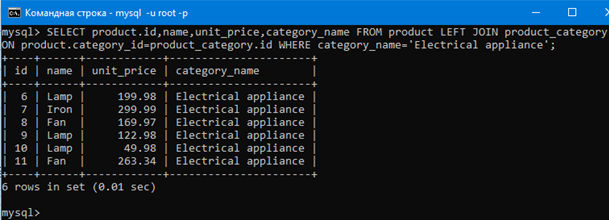
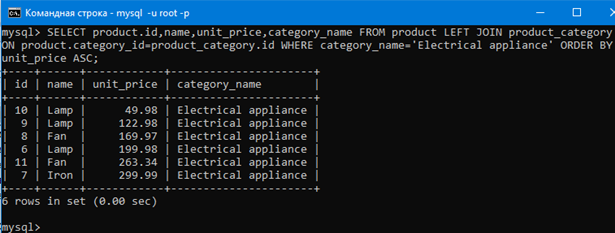
Например выведем только электроприборы sql командой:
SELECT product.id,name,unit_price,category_name FROM product LEFT JOIN product_category ON product.category_id=product_category.id WHERE category_name=’Electrical appliance’;
Видим, что мы применили WHERE к объединенной таблице и получили из нее только электроприборы.
И еше остался вопрос. Почему LEFT?
left означает, что мы объединяем именно левую таблицу с правой. Левая это та, которая стоит слева от LEFT JOIN, а правая, которая справа от LEFT JOIN.
Почему это так важно, что именно левую с правой? А то, что в результирующей объединенной таблице строки из левой таблицы будут обязательно все до последней, а из правой только те строки, которым нашлась пара в левой таблице.
Можно вместо left поставить right, тогда объединяем правую с левой и всё будет наоборот.
Также можно вообще без left и Right. Это называется Inner Join. Тогда в результирующей объединенной таблице будут только те строки из обеих таблиц, у которых есть пара. То есть если какой-то из строк в первой талице нет пары в другой или какой-то из строк во второй таблице нет пары в первой, то они в результирующую таблицу не попадут.
Также результат какого-либо запроса можно отсортировать с помощью ORDER BY.
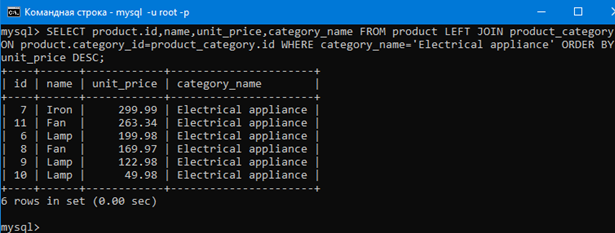
Например давайте отсортируем строки результата запроса ниже так чтобы они располагались в порядке уменьшения цены товара.
SELECT product.id,name,unit_price,category_name FROM product LEFT JOIN product_category ON product.category_id=product_category.id WHERE category_name=’Electrical appliance’;
Как видим, цена уменьшается сверху вниз. То есть сортировка строк происходит. DESC в конце значит от большего к меньшему.
Все. Самое главное по SQL разобрали.
Также еще нужно знать, что такое хранимые процедуры и транзакции, но их мы разберем когда будем учить JDBC и Hibernate
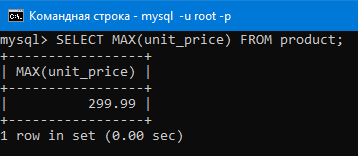
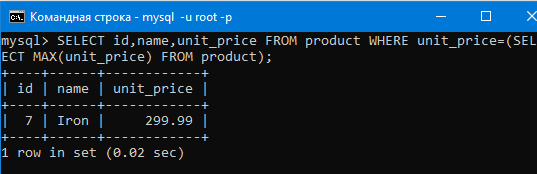
Теперь перейдем к подзапросам. Вот мы например вывели максимальное число в столбце.
Оно ясное дело тоже было в какой-то строке таблицы (строка с id 7 как можно увидеть ниже).
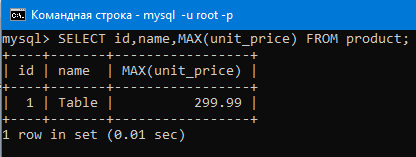
Как же нам вывести всю строку этого максимального числа (то есть мы хотим получить всю строку с id 7)?
Если мы сделаем так:
SELECT id,name,MAX(unit_price) FROM product;
То как видим, получаем не то, что нам нужно. id и name это значения из первой строки, а нам нужны те которые находятся в той же строке где находиться максимальное значение.
Чтобы всё получилось нужно использовать подзапрос.
Давайте выполним команду.
Первым SELECT-ом выбираются аттрибуты id,name,unit_price и из них выбирается только та строка где unit_price равное результату подзапроса(то есть второго SELECT, который в скобочках), а результатом подзапроса у нас будет максимальное значение в столбце unit_price.
То есть, как мы и хотели, вывело строку таблицы, в которой значение цены максимально. Вот так можно использовать подзапросы.
Далее разберем ключевое слово Group by и having. С помощью Group by можно разбить значения какого-либо выбираемого из таблицы аттрибута на группы.
Группы формируются так, что в каждую из них попадают строки с одинаковыми значениями указанного атрибута. То есть:
в одной группе — все строки с одним значением,
в другой — строки с другим значением,
в третьей — с ещё одним, и так далее.
На примере это будет гораздо понятнее 😉
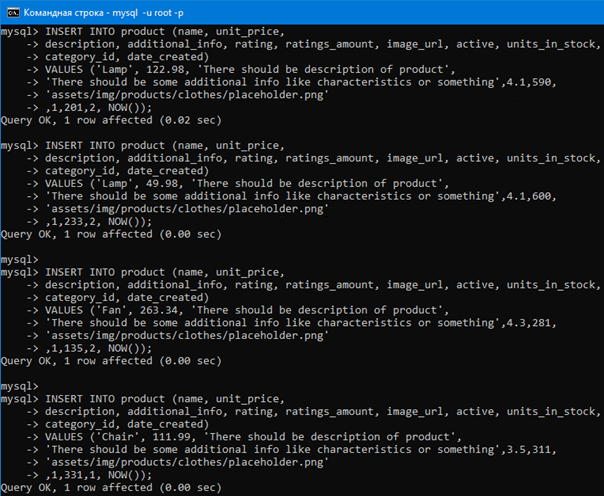
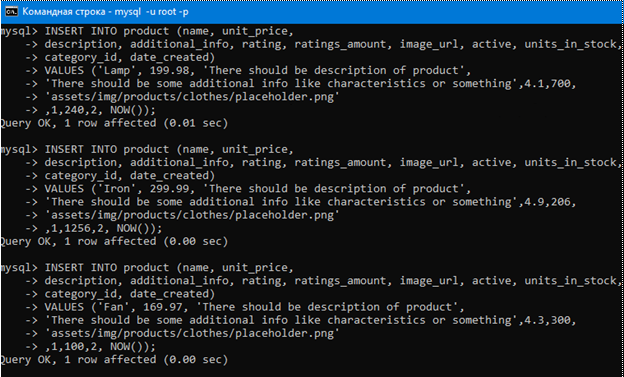
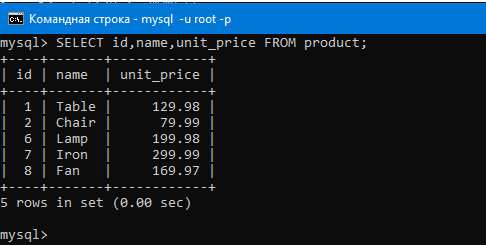
Для примера добавим в таблицу продукты из прошлых уроков еще пару ламп, еще один вентилятор и еще один стул. Это другие продукты, не те что были раньше, то есть у них будут другая цена, другое количество на складе и т.д. Ниже на картинке добавляем их (поскольку lamp, chair и др. будет повторяться несколько роз, можно представить, что мы добавили другие модели этих продуктов, хотя имя в таблице то же самое).
Добавили.
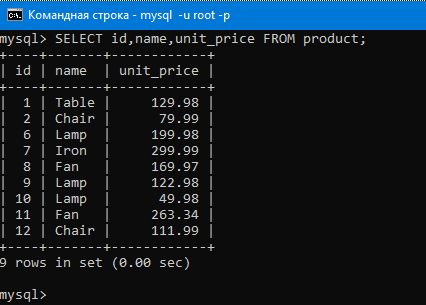
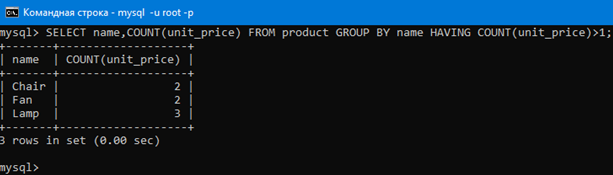
Теперь, что будет если мы совершим группировку по имени (вот так GROUP BY(name)).
Как уже было сказано, GROUP BY засовывает в одну группу одинаковые значения столбца. Групп в итоге будет пять, так как у нас пять разных значений в столбце name.
То есть в первой группе будут три лампы, во второй два вентилятора, в третьей два стула, в четвертой один стол, в пятой один утюг. И самое интересное, что к каждой из этих групп мы можем применить какую-нибудь агрегатную функцию.
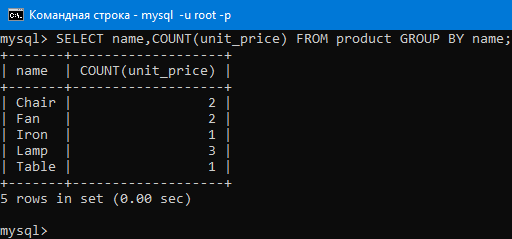
Давайте сгруппируем по имени и найдем количество продуктов в каждой группе командой:
SELECT name,COUNT(unit_price) FROM product GROUP BY name;
Как видим, результат соответствует тому, что было описано выше.
Запрос происходит в такой последовательности:
Сначала выбираются два столбца — name и unit_price. Потом строки группируются по значению name: все, где name = 'лампа', в одной группе, где name = 'вентилятор' — в другой и т.д. После этого для каждой группы считается, сколько в ней строк — с помощью COUNT(unit_price).
И теперь мы подошли к ключевому слову HAVING, которое используется ТОЛЬКО ЕСЛИ перед ним использовалось GROUP BY.
Представим, что над результатом того что получилось в результате предыдущей команды с GROUP BY нам нужно выполнить ЕЩЕ какие-то действия, то есть отфильтровать результат команды SELECT name,COUNT(unit_price) FROM product GROUP BY name; еще по какому-нибудь дополнительному условию.
Для этого применяется HAVING.
Для примера давайте выведем только те строки предыдущего результата, у которых COUNT(unit_price) больше 1. Это можно сделать запросом SELECT name,COUNT(unit_price) FROM product GROUP BY name HAVING COUNT(unit_price)>1;
Теперь вывелись только группы, в которых колличество строк больше 1.
Агрегатная функция может выполнить какие-либо операции над всеми значениями столбца или над группой значений этого столбца и как результат этих операций вернуть одиночное значение.
Например:
Можно сложить все значения числового столбца или сложить группу значений этого столбца с помощью функции SUM(), или вывести среднее арифметическое функцией AVG() или с помощью COUNT() посчитать количество строк в столбце, с помощью MIN() можно найти минимальное числовое значение в столбце, с помощью MAX() максимальное.
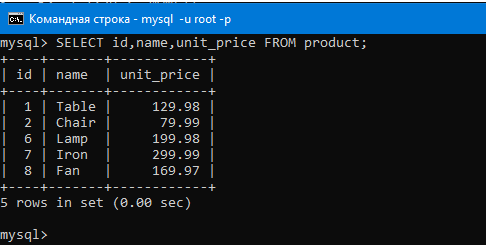
Посмотрим еще раз на таблицу перед вводом команды с функцией:
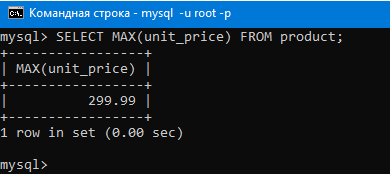
Теперь давайте выведем максимальное значение в столбце с ценой товара
Видим что вывело максимальное значение столбца, то есть 299.
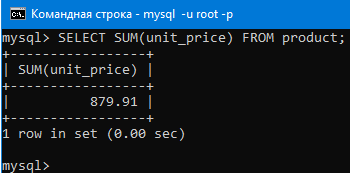
Можно вывести сумму всех значений в столбце с ценой.
Другие функциииспользуються подобным образом, разбирать их всех не будем.
В следующую группу команд под названием DML входят команды для манипулирования данными, а именно:
команда SELECTдля выборки данных из таблицы,
команда INSERTдля вставки данныхв таблицу,
команда DELETE для удаления строки таблицы
команда UPDATE для изменения строки таблицы.
Воспользуемся такими insert запросами для добавления категорий в таблицу с категориями.
# INSERT INTO product_category – означает добавить
# в таблицу product_category.
# Далее в скобочках перечисляем аттрибуты,
# в которые мы собираемся
# добавить данные. В скобочках после VALUES
# указываем значения, которые будут
# вставляться в аттрибуты, которые мы
# указали в предыдущих скобках.
INSERT INTO product_category(category_name)
VALUES (‘Forniture’);
INSERT INTO product_category(category_name)
VALUES (‘Electrical appliance’);
Воспользуемся такими insert запросами для добавления продуктов в таблицу с продуктами.
# Добавляем стол. Как видим здесь уже
# в скобках больше имен аттребутов
# и значений аттребутов чем в прошлых
# insert запросах. В таком случае
# вставка происходит так: ‘Table’
# вставляется в столбец name, 129.98
# в столбец unit_price, ‘There should
# be description of product’
# в столбец description и т.д. Думаю
# порядок добавления понятен.
INSERT INTO product (name, unit_price,
description, additional_info, rating,
ratings_amount, image_url, active,
units_in_stock, category_id, date_created)
# здесь видим что в аттребут
# category_id (то есть в столбец внешнего
# ключа) записано значение 1, что значит
# что стол (‘Table’) имеет
# категорию ‘Furniture’ (Мебель с англ.).
VALUES (‘Table’, 129.98, ‘There should be
description of product’, ‘There should be
some additional info like characteristics
or something’, 4.5, 131,
‘assets/img/products/clothes/placeholder.png’,
1, 50, 1, NOW());
# Подобным образом добавляем стул.
INSERT INTO product (name, unit_price,
description, additional_info, rating,
ratings_amount, image_url, active, units_in_stock,
category_id, date_created)
VALUES (‘Chair’, 79.99, ‘There should be
description of product’, ‘There should be some
additional info like characteristics or something’,
3.5, 327, ‘assets/img/products/clothes/placeholder.png’,
1, 300, 1, NOW());
# И т.д.
# Только здесь уже внешний ключ 2, так
# как лампа – это электроприбор.
INSERT INTO product (name, unit_price, description,
additional_info, rating, ratings_amount, image_url,
active, units_in_stock, category_id, date_created)
VALUES (‘Lamp’, 199.98, ‘There should be
description of product’, ‘There should be some
additional info like characteristics or something’,
4.1, 700, ‘assets/img/products/clothes/placeholder.png’,
1, 240, 2, NOW());
INSERT INTO product (name, unit_price, description,
additional_info, rating, ratings_amount, image_url,
active, units_in_stock, category_id, date_created)
VALUES (‘Toaster’, 299.99, ‘There should be description
of product’, ‘There should be some additional info
like characteristics or something’, 4.9, 206,
‘assets/img/products/clothes/placeholder.png’,
1, 1256, 2, NOW());
INSERT INTO product (name, unit_price, description,
additional_info, rating, ratings_amount, image_url,
active, units_in_stock, category_id, date_created)
VALUES (‘Fan’, 169.97, ‘There should be description
of product’, ‘There should be some additional info
like characteristics or something’, 4.3, 300,
‘assets/img/products/clothes/placeholder.png’,
1, 100, 2, NOW());
Давайте воспользуемся этими запросами.
Добавим категории в таблицу категорий.
Добавим продукты в таблицу с продуктами.
Теперь познакомимся с командой, которую вы будете чаще всего использовать.
Это команда SELECT для выборки данных из таблицы.
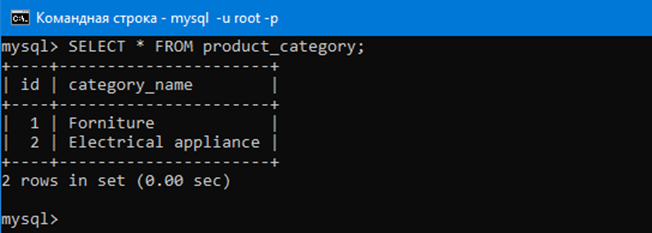
Выбирать все данные из таблицы с категориями можно с помощью запроса:
SELECT * FROM product_category;
После select указываются имена атрибутов данные, которых мы хотим выбрать из таблицы. В данном случае указана *, что значит что нужно выбрать данные вообще всех атрибутов в таблице.
После from указывается из какой таблицы мы собираемся выбирать данные аттрибутов. В данном случае из таблицы product_category.
Таким образом вбив данную команду в mysql консоли можно увидеть всё содержимое таблицы product_category.
Таким образом мы выбрали данные всех аттрибутов в таблице. Аттрибута там два – id и category_name.
Эти данные, как мы помним, мы туда ранее добавляли с помощью insert.
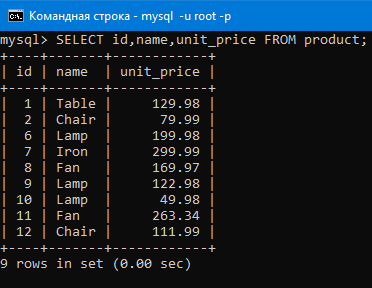
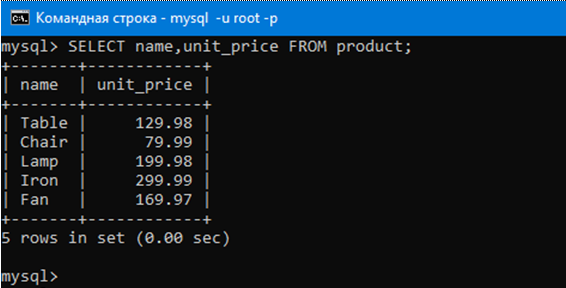
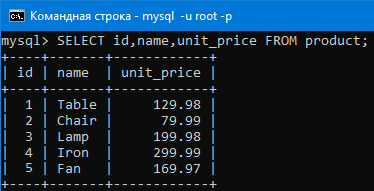
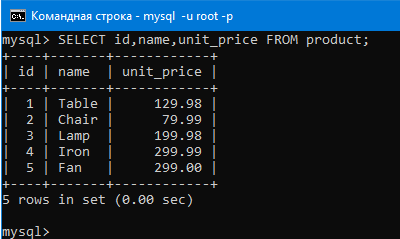
Теперь выберем столбцы name и unit_price из таблицы с продуктами запросом:
SELECT name,unit_price FROM product;
Видим, что мы выбрали этой командой только два аттрибута.
Как же нам теперь выбрать отдельную строку или несколько строк таблицы, а не все строки?
Для этого существует слово Where.
Приведем пример.
Перед этим мы выводили все строки аттрибутов name и unit_price.
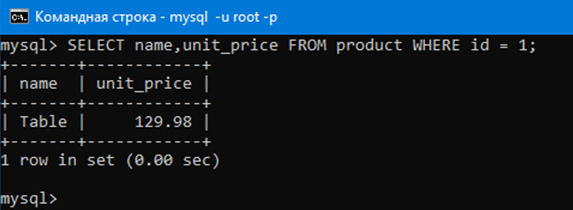
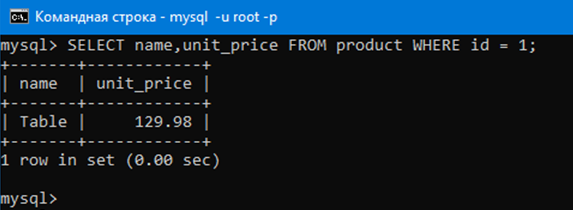
Теперь выведем только те строки аттрибутов name и unit_price где в аттрибуте id стоит 1. Ясное дело это будет одна строка, так как мы извлекаем по ключу id.
Это можно сделать командой:
SELECT name,unit_price FROM product WHERE id = 1;
Как видим, мы получили одну строку. Эта строка, в которой ячейка аттрибута id равна единице. Давайте даже проверим это:
Действительно, как видим Table, 129,98 и 1 находятся в одной строке.
Словом SELECT мы задаем какие аттрибуты выбирать, а словом where какие строки. Точнее говоря словом Where мы задаем условие по которому происходит выборка строк.
Выберем теперь несколько строк и также выведем аттрибут id.
Как видим мы воспользовались ключевым логическим оператором or(или).
В условиях можно писать все стандартные логические операторы and, or или not.
А в данном случае мы запросили строки таблицы с продуктами где в ячейке аттрибута id находиться 2 или 4.
То есть мы достаем обе строки с помощью or, а не and, как на первый взгляд многим может показаться нужно делать.
Далее разберем ключевое слово Update. Оно нужно для обновления каких-либо строк таблицы по какому-то условию.
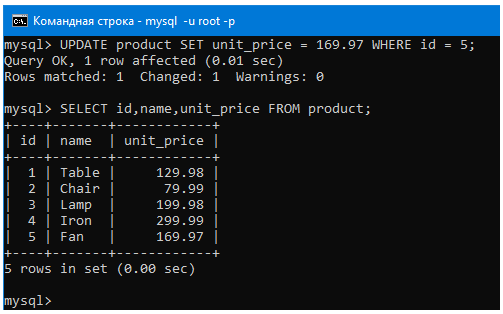
Например, изменим строку таблицы где ячейка аттрибута id = 5. Менять мы будем ячейку аттрибута цены продукта в этой строке.
Для этого воспользуемся запросом:
UPDATE product SET unit_price = 299 WHERE id = 5;
Посмотрим теперь содержимое таблицы после изменений:
Как мы помним, в строке где id был 5 цена была 169.97, теперь она изменилась на 299.
Вернем обратно с помощью запроса:
UPDATE product SET unit_price = 169.97 WHERE id = 5;
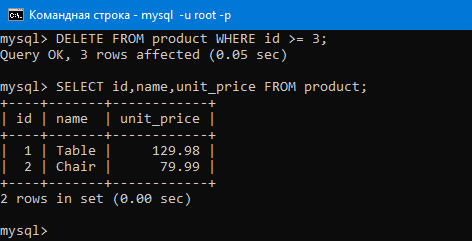
Далее разберем ключевое слово Delete. Оно нужно для удаления строк таблицы.
Например, удалим строки таблицы у которых id >= 3. То есть удалиться строка с id=3, строка с id=4 и строка с id=5.
Сделаем это с помощью запроса:
DELETE product WHERE id >= 3;.
Как видим, три последние строки таблицы удалились.
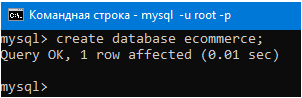
Командой create database создадим базу данных с именем ecommerce, то есть интернет магазин.
Перед прохождением раздела по SQL очень желательно пройти предыдущий раздел по базам данных чтобы всё было понятно 😉
Команды работы с БД делятся на группы. Рассмотрим группу DDL.
В нее входят команды определения структуры данных в БД. Точнее говоря команды для создания таблиц и удаления.
Создать таблицу можно командой create table, удалить – drop table.
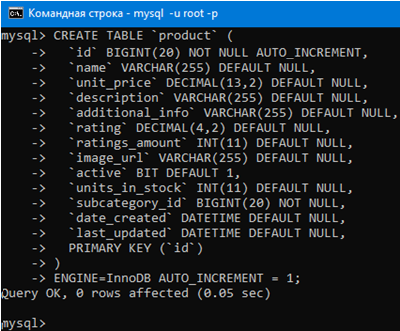
Запрос для создания таблицы с продуктами выглядит так:
# Комментарии в SQL это два прочерка “--” или “#”
# Создаем таблицу с именем products
CREATE TABLE `product` (
# Здесь в скобочках команды CREATE TABLE
# определяем атрибуты таблицы, в которые
# потом будем записывать данные.
# Добавляем атрибут `id`. В столбце этого
# атрибута будут храниться ключи продуктов.
# Ключи будут числового типа BIGINT.
# В скобках после типа всегда указывается
# количество символов. То есть максимум
# число может содержать 20 цифр.
# С помощью NOT NULL указываем, что столбец
# не может содержать пустых значений.
# С помощью AUTO_INCREMENT указываем, что
# при добавлении новой строки в таблицу
# не нужно будет вписывать значение в этот столбец вручную
# вместо этого будет автоматически увеличиваться
# последнее значение, которое присутствовало на единицу
# значение, которое присутствовало в этом
# столбце перед добавлением новой строки,
# и получившееся увеличенное значение будет
# ключом новой добавляемой строки.
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
# Добавим атрибут `name` – будут храниться
# наименования продуктов. VARCHAR значит, что
# этот атрибут будет хранить строковые
# значения.
`name` VARCHAR(255) DEFAULT NULL,
# цена продукта. DECIMAL – дробное значение
`unit_price` DECIMAL(13,2) DEFAULT NULL,
# и т.д.
`description` VARCHAR(255) DEFAULT NULL,
`additional_info` VARCHAR(255) DEFAULT NULL,
`rating` DECIMAL(4,2) DEFAULT NULL,
`listings_amount` INT(11) DEFAULT NULL,
`image_url` VARCHAR(255) DEFAULT NULL,
`is_active` BIT DEFAULT 1,
`units_in_stock` INT(11) DEFAULT NULL,
`date_created` DATETIME DEFAULT NULL,
`last_updated` DATETIME DEFAULT NULL,
# С помощью PRIMARY KEY указываем, какой
# атрибут будет ключом в таблице.
PRIMARY KEY (`id`)
)
ENGINE=InnoDB AUTO_INCREMENT = 1;
Теперь давайте используем этот запрос чтобы создать таблицу с продуктами.
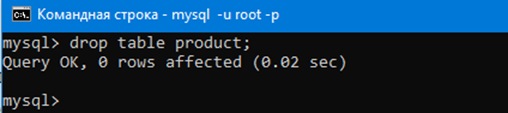
Теперь удалим таблицу.
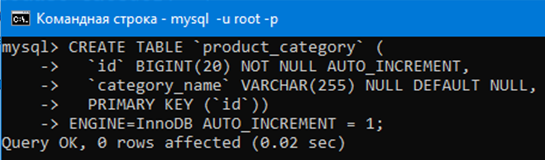
Давайте теперь сначала создадим таблицу с категориями продуктов, а потом таблицу продуктов чтобы потом соединить их связью Один ко Многим с помощью внешнего ключа.
Воспользуемся таким запросом для создания таблицы с категориями (здесь ничего нового):
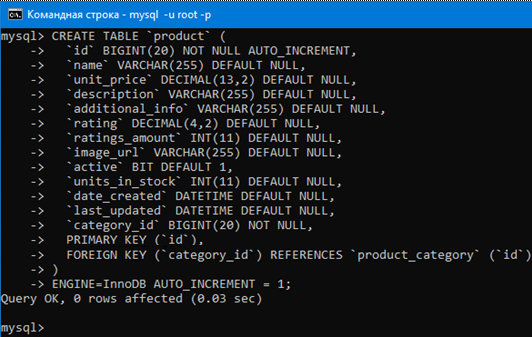
Теперь воспользуемся таким запросом чтобы опять создать таблицу с продуктами, но уже со столбцом внешнего ключа и конструкцией для связывания таблиц с его помощью.
CREATE TABLE `product` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`unit_price` DECIMAL(13,2) DEFAULT NULL,
`description` VARCHAR(255) DEFAULT NULL,
`additional_info` VARCHAR(255) DEFAULT NULL,
`rating` DECIMAL(4,2) DEFAULT NULL,
`ratings_amount` INT(11) DEFAULT NULL,
`image_url` VARCHAR(255) DEFAULT NULL,
`active` BIT DEFAULT 1,
`units_in_stock` INT(11) DEFAULT NULL,
`date_created` DATETIME DEFAULT NULL,
`last_updated` DATETIME DEFAULT NULL,
# Добавляем столбец внешнего ключа.
`category_id` BIGINT(20) NOT NULL,
# В category_id будут храниться ключи
# из таблицы с категориями.
# Таким образом мы связываем строки двух таблиц.
PRIMARY KEY (`id`),
# Связанный столбец `category_id` в этой таблице
# с ключом `id` из таблицы `product_category`
# с помощью конструкции FOREIGN KEY … REFERENCES …
FOREIGN KEY (`category_id`) REFERENCES `product_category` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT = 1;
Теперь мы можем вводить SQL команды для работы с СУБД.
Давайте воспользуемся этими запросами.
Создадим таблицу категорий.
Создадим таблицу продуктов, которая будет связана с таблицей категорий с помощью внешнего ключа.
Теперь при заполнении таблицы продуктов в столбец category_id нужно будет для каждого продукта писать ключ соответствующей ему категории из другой таблицы. Это увидим в следующем уроке.
Теперь разберемся как же работать с Базой Данных. То есть как создать таблицу, добавить в нее данные, извлечь из нее данные, удалить ееи т.д. Для этого используется язык запросов к БД – SQL.
Для начала нужно узнать где же хранить нашу базу данных, и через как с ней работать SQL запросами.
Для этого используется система управления базами данных (СУБД). Таких систем есть много – MySQL, Postgresql, MongoDB и другие.
Будем использовать MySQL, так как на ней принято учиться, хотя она используется не только для учебы, а и во вполне серьезных проектах.
MySQL нужно скачать. Переходим по ссылке https://dev.mysql.com/downloads/installer/.
Нажимаем на второй Download, потом No thanks, just start my download. И происходит скачивание Mysql.
Открываем скачанный файл -> выбираем custom -> Далее везде next -> когда попросят создать пароль вы его создаете -> далее всё next.
Далее переходим в папку C:\Program Files\MySQL. Переходим в папку bin и копируем путь C:\Program Files\MySQL\MySQL Server 5.5\bin.
Переходим в изменение системных переменных также как мы добавляли javac ранее в самых первых уроках и добавляем в path только что скопированный путь C:\Program Files\MySQL\MySQL Server 5.5\bin.
Теперь через командную строку можем работать с СУБД.
Переходим в режим работы с MySQL командой mysql -u root -p.
Теперь мы можем вводить SQL команды для работы с СУБД.