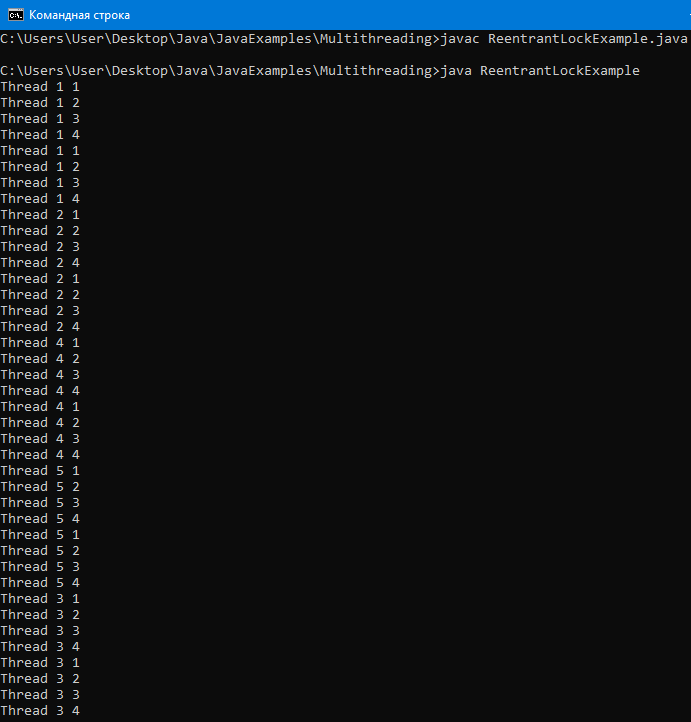
fork/join framework – для разбиения задачи на подзадачи и чтобы эти подзадачи выполнялись в отдельных потоках.
Также эти подзадачи могут тоже делиться на подзадачи и опять же чтобы эти подзадачи выполнялись в отдельных потоках.
Повторяться этот процесс деления может пока подзадача не станет необходимо мала.
Есть пул потоков. В один из его потоков ставиться большая задача.
Эта задача и подзадачи в будущем являют собой выполнения метода compile, который нужно переопределить
Переопределяется он всегда похожим образом:
if задача или подзадача уже необходимо мала, возвращаем что-то из метода compile.
else – делим задачу или подзадачу на подзадачи.
Деление на подзадачи в else происходит особым рекурсивным образом с помощью методов fork и join.
fork добавляет подзадачу в пул потоков и любой свободный поток может ее подхватить для выполнения. fork вызывает метод compile подзадачи, к которой fork был применен.
join ждет пока эта форкнутая подзадача выполнится.
Внимание джойном останавливается выполнение кода, но поток не блокируется, поток может выполнять другую подзадачу из пула потоков.
join возвращает значение из compile, который fork вызвал.
Ясное дело, compile будет вызываться рекурсивно форком и соответственно джойны будут копиться пока не дойдет до наименьшей подзадачи.
И джойны, понятное дело, в обратном направлении начнут освобождаться.
Помещенные задачи форком в любом потоке в пул потоков могут быть взяты любым свободным потоком для выполнения.
В этом и есть профит, то что задача распараллеливается и любой поток может взять любую подзадачу для выполнения, даже если она была сгенерирована другим потоком.
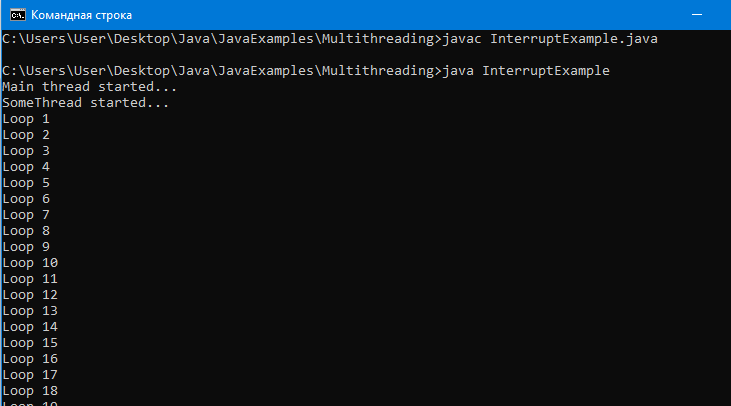
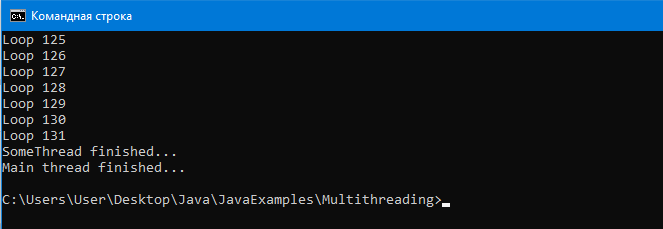
Пример программы:
Вывод:
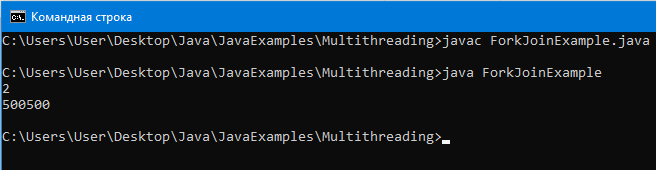
Как можно увидеть, в консоли сумма чисел от 1 до 1000 посчитана верна – 500500.