Последний вид связи – это Один-к-одному.
Этот вид связи самый простой.
Как понятно из названия, каждой строке одной таблицы соответствует только одна строка в другой.
Почти не используется за редкими исключениями, так как очевидно, что соединение таблиц связанных таким образом в одну не приведет к дублированию данных.
Но бывают случаи когда это бывает полезно.
Самый полезный случай – это когда мы хотим отделить из основной таблицы данные, которые относятся только к ее части.
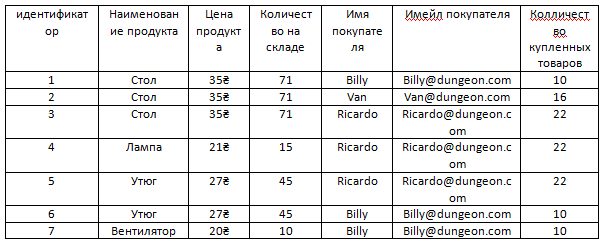
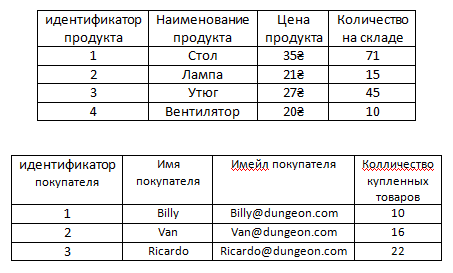
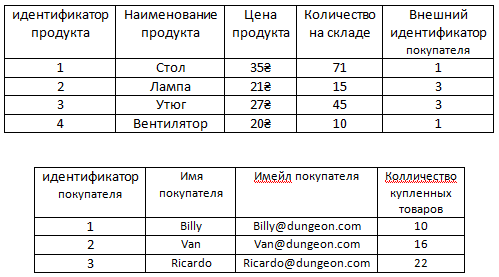
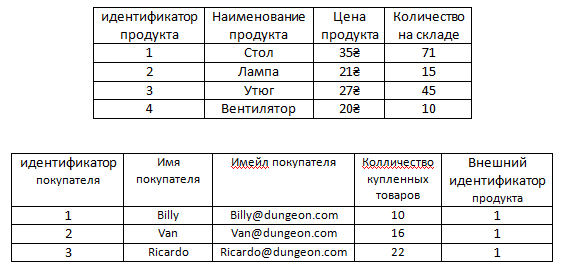
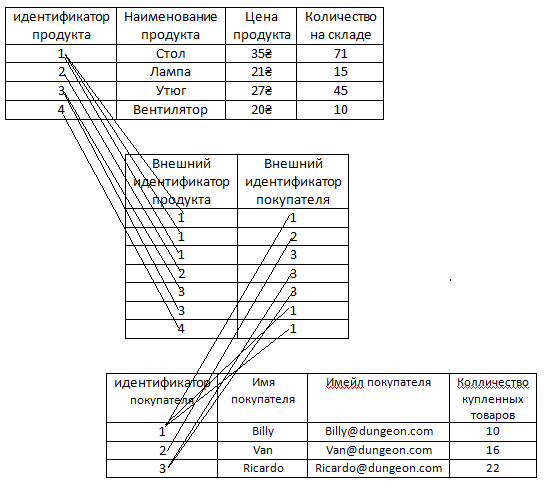
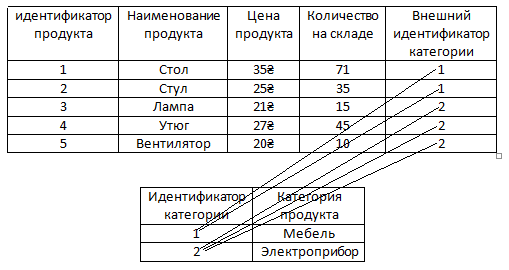
Например, есть наша основная таблица Продукты.
И пусть в ней будет новый аттрибут – Бракованный товар. То есть например, все лампы из тех, что есть на складе оказались бракованными или все стулья, которые есть на складе оказались бракованными. То есть представим, что эти все стулья и лампы это какая-то конкретная их модель и эта модель выпускалась с браком, такое бывает. Тогда у них в этом столбце будет стоять true, то есть бракованные, если всё в порядке то false.
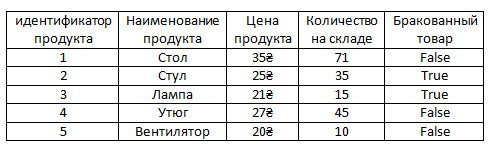
Так вот, очевидно, что у большей части продуктов в таблице будет стоять false. Так как такой массовый брак какого-то продукта это скорее редкость.
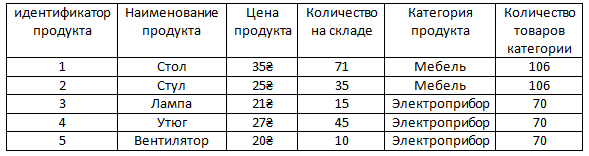
Для того чтобы нам не хранить информацию в таблице с продуктами о том, что с ними всё в порядке можно вынести информацию о том, что какие-то продукты бракованные в отдельную таблицу.
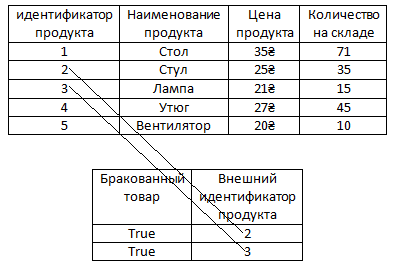
И ясное дело в этой новой таблице, как видим, намного меньше записей, чем если бы информация о браке хранилась в формате столбца в таблице с продуктами, так как уже было сказано в ней нет информации о том, что какие-то продукты не бракованные. То есть, как видим, в ней нету false, эту информацию в этой таблице хранить незачем, поскольку если у какого-то продукта нету связанной строки в таблице барка, это само по себе значит, что продукт не бракованный. То есть у стола, утюга и вентилятора нету связи с таблицей брака и это само по себе значит, что с этими продуктами всё в порядке.
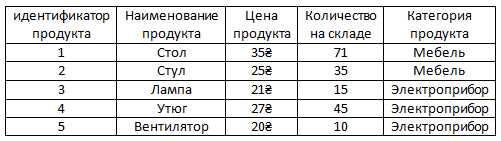
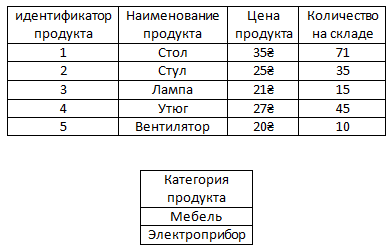
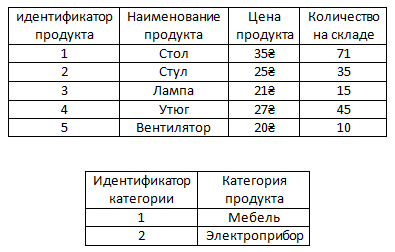
Второй случай использования связи Один-к-одному – это если, например, в таблице слишком много столбцов, то чтобы ее немного уменьшить можно некоторые столбцы вынести в отдельные таблицы.
Третий случай – это когда у нас, например, есть таблица с продуктами и у продуктов появляется какой-то новый ВРЕМЕННЫЙ аттрибут. То есть мы точно знаем, что этот столбец мы со временем удалим из таблицы. И создавать новый столбец в основной таблице не всегда бывает удобно, легче создать отдельную таблицу чтобы потом с легкостью ее удалить.
Четвертый случай – это из соображений безопасности. То есть если злоумышленник получит доступ к основной таблице, а в ней есть какие-то очень секретные аттрибуты, то он может просто пройтись по строкам таблицы и выбрать эти все секретные данные. очевидно безопаснее было бы хранить эти секретные данные в виде отдельных таблиц чтобы хацкер не смог получить их всех скопом.
ВСё!! С информацией полученной в этом разделе курса вы сможете спроектировать реляционную БД любой сложности.