FileOutputStream, FileInputStream – для чтения файла и записи в файл.
В конструкторе должен быть указываем путь к файлу с которым будем совершать ввод/вывод.
Пример программы:
import java.io.*;
import java.util.*;
class FileStreamLesson {
public static void main(String[] args) {
try {
// FileOutputStream – для записи в файл. В конструктор
// FileOutputStream передаем в виде строки путь к файлу
// в который будем записывать.
// Если полноценный путь не указан, а только файл, значит
// файл, который мы собираемся читать/записывать находится
// в той же папке где и текущий файл java в который вы
// сейчас смотрите.
FileOutputStream fileOutputStream =
new FileOutputStream(“person.txt”);
// FileInputStream – для чтения файла. Также передаем путь
FileInputStream fileInputStream =
new FileInputStream(“person.txt”);
// Поскольку это OutputStream и InputStream значит, что
// читать из файла или записывать в файл будем байты.
// Поэтому чтобы записать в файл строку String
// ее сначала нужно преобразовать в массив байтов,
// и а его уже записывать в файл. Ниже это делаем.
// Строка которую будем записывать
String str = “Some Text”;
// преобразовываем строку в байты
byte[] buff = str.getBytes();
// через поток записи в файл записываем туда массив байт
fileOutputStream.write(buff, 0, buff.length);
// Теперь прочитаем из файла person.txt
// только что нами записанную строку.
// available возвращает текущее количество байтов в файле
// и пока оно больше нуля цикл продолжается.
int i;
while (fileInputStream.available() > 0) {
// с помощью read на каждой итерации цикла
// считываем один байт и записываем в переменную int.
// и после read возвращаемое количество байтов
// через метод available уменьшается на 1
i = fileInputStream.read();
// также необходимо привести к символу
// полученный из файла байт
System.out.println((char) i);
}
} catch (Exception e) {
}
}
}
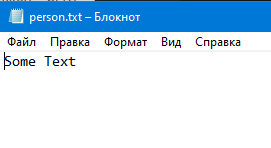
После fileOutputStream.write(buff,0,buff.length); в файл person.txt записывается “Some Text” и файл выглядит так:
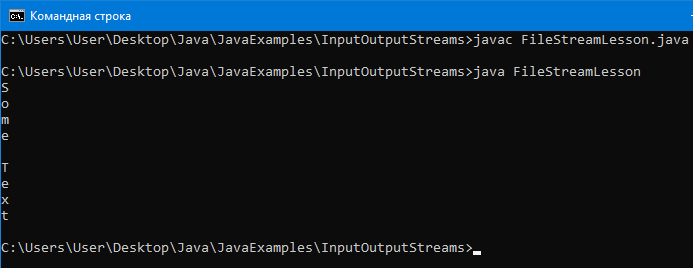
Циклом побайтно считается файл с помощью FileInputStream:
Часто так бывает, что нам нужно ввести куда-то информацию и откуда-то ее вывести. Например, извлечь что-нибудь из файла или записать туда что-либо.
При этом логично, что разные источники (будь-то файл или консоль или что-либо еще) с которыми мы совершаем ввод/вывод различны по своему устройству, соответственно и средства для взаимодействия с этими разными источниками должны быть разными. Например, чтобы вводить информацию в файлик и выводить информацию из файлика используются одни средства, а для ввода/вывода в консоль уже другие средства, для ввода/вывода куда-то еще другие.
Java предоставляет множество разных средств (разных классов) для ввода/вывода будь-то работа с файлами, консолью или другими источниками.
В Java есть два основных вида классов-потоков для ввода-вывода:
Inputstream, Outputstream – ввод/вывод куда-либо неструктурированной последовательности байтов. (представляют удобные средства для передачи байтов)
Writer, Reader – ввод/вывод куда-либо последовательности символов Unicode (представляют удобные средства для передачи символов).
У этих классов есть подклассы. В этом уроке мы разберем потоки PrintWriter и PrintStream.
PrintWriter и PrintStream
Рассмотрим PrintWriter и PrintStream.
Самые простые потоки ввода/вывода – это System.in и System.out. Для ввода и вывода информации в консоль соответственно.
out – это на самом деле объект класса PrintStream. print()println() – методы этого класса. Поток PrintStream с помощью print() или println() превращает переданный аргумент в один из этих методов в строку и передает в другой поток вывода куда-нибудь.
out создан за кулисами так, чтобы он выводил информацию в консоль.
PrintWriterPrintStream (нужны для передачи строк в поток) – print() println() превращают переданные аргументы в строки и передают их в какой-то поток.
PrintStreamпечатает на OutputStream, а PrintWriter – на Writer(основное преимущество Writer, что можно указать кодировку).
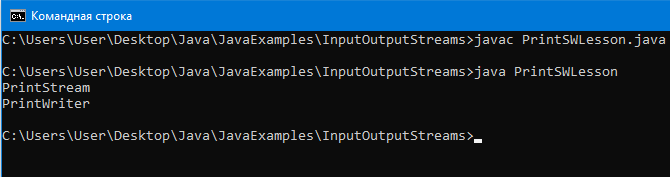
Пример программы:
import java.io.*;
import java.util.*;
class PrintSWLesson {
public static void main(String[] args) {
//так как System.out объект PrintStream можем сделать так
PrintStream ps = System.out;
ps.println(“PrintStream”);
//или с помощью PrintWriter. В конструктор передаем поток,
//в который будем передавать строку с помощью println
//в данном случае поток вывода в консоль System.out
PrintWriter pw = new PrintWriter(System.out);
pw.println(“PrintWriter”);
pw.flush(); //про flush чуть позже
}
}
Благодаря классам реализующим Set можно создать массив в которомэлементы не повторяются.
HashSetэто как hashmap, только без значений, только ключи.
В hashset могут храниться только уникальные ключи, благодаря уже ранее упомянутому hashcode, который есть у каждого элемента добавляемого в hashset.
Поясним на примере:
import java.util.*;
public class Set {
public static void main(String[] args) {
// создаем коллекцию
HashSet hSet = new HashSet();
// добавление элемента
hSet.add(“Sunday”);
hSet.add(“Monday”);
hSet.add(“Sunday”);
hSet.add(“Tuesday”);
// удаление элемента
hSet.remove(“Monday”);
// в hashset нету get поэтому сначала нужно преобразовать
// в массив а потом извлекать либо использовать iterator
String[] hSetArr = hSet.toArray(new String[hSet.size()]);
for(int i = 0; i < hSetArr.length; i++) {
System.out.println(hSetArr[i]);
}
// проверка на наличие элемента в списке
System.out.println(hSet.contains("Tuesday"));
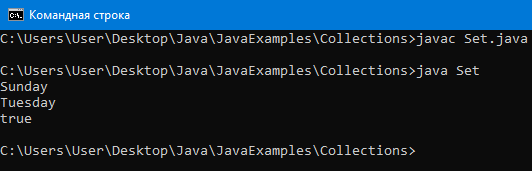
// Как можно увидеть по результатам в массиве всего один Sunday
}
}
Вывод:
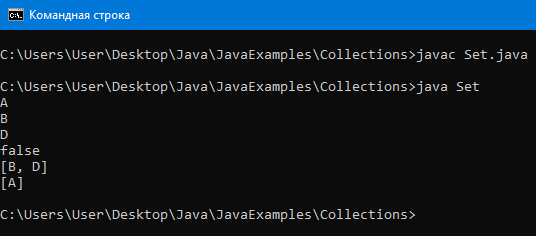
TreeSet
TreeSet – хранит элементы в виде дерева, что позволяет быстрее искать элементы.
Все элементы отсортированы и не повторяются.
TreeSet лучше всего подходит для нахождения диапазонов.
Пример программы:
import java.util.*;
public class Set {
public static void main(String[] args) {
// создаем коллекцию
TreeSet tSet = new TreeSet();
// добавление элемента
tSet.add(“D”);
tSet.add(“B”);
tSet.add(“A”);
tSet.add(“C”);
tSet.add(“E”);
// удаление элемента
tSet.remove(“C”);
// В TreeSet нету get поэтому сначала нужно преобразовать
// в массив а потом извлекать либо использовать iterator
String[] tSetArr = tSet.toArray(new String[tSet.size()]);
for(int i = 0; i < tSetArr.length; i++) {
System.out.println(tSetArr[i]);
}
// проверка на наличие элемента в списке
System.out.println(tSet.contains("П"));
// для нахождения диапазона
System.out.println(tSet.tailSet("B"));
System.out.println(tSet.headSet("B"));
// Как можно увидеть по результатам в массиве
// всего один В и элементы хранятся в алфавитном порядке
}
}
Вывод:
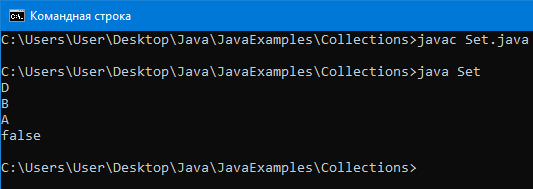
LinkedHashSet
LinkedHashSet – хранит элементы в порядке вставки и элементы не повторяются.
Опять таки, лучше использовать когда элементы часто вставляются/удаляются.
Пример программы:
import java.util.*;
public class Set {
public static void main(String[] args) {
// создаем коллекцию
LinkedHashSet ltSet = new LinkedHashSet();
// добавление элемента
ltSet.add(“D”);
ltSet.add(“B”);
ltSet.add(“A”);
ltSet.add(“C”);
ltSet.add(“B”);
// удаление элемента
ltSet.remove(“C”);
// LinkedHashSet нету get поэтому сначала нужно преобразовать
// в массив а потом извлекать либо использовать iterator
String[] ltSetArr = ltSet.toArray(new String[ltSet.size()]);
for(int i = 0; i< ltSetArr.length; i++) {
System.out.println(ltSetArr[i]);
}
// проверка на наличие элемента в списке
System.out.println(ltSet.contains("B"));
//Как можно увидеть по результатам в масиве всего один В
// элементы хранятся в порядке вставки
}
}
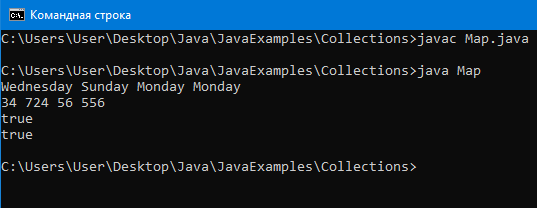
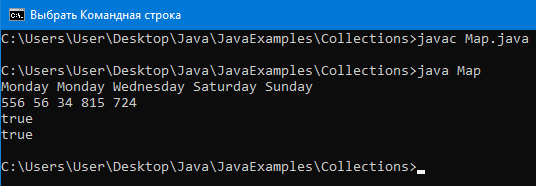
Благодаря классам реализующим Map можно создать массив из пар ключ-значение. То есть один элемент этого массива это пара.
Пример программы:
import java.util.*;
public class Map {
public static void main(String[] args) {
//создаем коллекцию
HashMap< Integer, String > hMap = new HashMap< Integer, String >();
//добавление элемента
//видим числовой ключ и соответствующее ему значение
hMap.put(34, “Sunday”);
hMap.put(56, “Monday”);
hMap.put(85, “Tuesday”);
hMap.put(34, “Wednesday”);
hMap.put(556, “Monday”);
hMap.put(724, “Sunday”);
// удаление элемента
hMap.remove(85);
//В hashset нету get по индексу и не наследует iterator
//поэтому передаем значения с помощью метода values
//в конструктор другой коллекции, которую можно перебирать.
ArrayList< String > hMapValues = new ArrayList< String >(hMap.values());
for(int i = 0; i < hMapValues.size(); i++) {
System.out.print(hMapValues.get(i) + " ");
}
System.out.println();
//или keySet если нужно перебирать ключи
ArrayList< Integer > hMapKeys = new ArrayList< Integer >(hMap.keySet());
for(int i = 0; i < hMapKeys.size(); i++) {
System.out.print(hMapKeys.get(i) + " ");
}
System.out.println();
// проверка на наличие элемента с таким ключем в списке
System.out.println(hMap.containsKey(56));
// проверка на наличие элемента с таким значением в списке
System.out.println(hMap.containsValue("Sunday"));
// можно также получить значение элемента hashmap по ключу
System.out.println(hMap.get(34));
}
}
Вывод:
Hash коллекции внутри
Довольно важно знать как Hash коллекции работают под капотом.
HashMap под капотом разбит на 16 linkedlist в которых собственно и хранятся пары. То есть сам HashMap это тоже массив из 16 ячеек, но каждая ячейка представляет собой отдельный LinkedList.
Добавление элемента в HashMap происходит так, что сначала по ключу вычисляется некий код, который называется hashcode, а по нему индекс нужного LinkedList-а в массиве из 16 LinkedList и в linkedlist-е с этим индексом сохраняется элемент.
При выборке из HashMap, например с помощью get, ранее вставленного элемента, будет происходить тот же процесс, что и при его вставке, то есть расчет hashcode по ключу, который был передан в get и собственно выборка из того linkedlist-а который соответствует рассчитанному hashcode.
Например:
Очевидно, что и при вставке, например, ключа 10, и при выборке по этому ключу будет рассчитан один и тот же hashcode. Соответственно и вставка ключа 10 и выборка по ключу 10 будет происходить в одном и том же linkedlist-е.
Для ключа, например 13, вставка и выборка уже, возможно, попадет на другой linkedlist. А возможно попадет на тот linkedlist где перед перед этим вставилось 10. Зависит от рассчитанного hashcode для числа 13.
Отсюда очевиден смысл hashmap, что поскольку мы и вставляем и выбираем в одном и том же linkedlist-e, то выборка ясное дело всегда идет в одном из 16 linkedList-ов, а не во всех, и это ясное дело лучше, чем если бы мы вибирали из всех шестнадцати как в одном большом linkedlist-e.
Также важно упомянуть, что поиск нужного linkedlist-a из 16 по hashcode происходит за константное время, проще говоря скорость лучше не бывает.
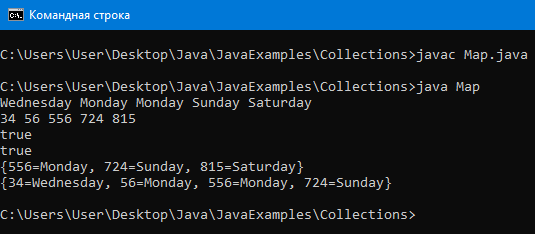
TreeMap
TreeMap – хранит пары в виде дерева, что позволяет быстрее искать элементы.
Все элементы отсортированы по ключу.
TreeMap лучше всего подходит для нахождения диапазонов
Пример программы:
import java.util.*;
public class Map {
public static void main(String[] args) {
// создаем коллекцию
TreeMap< Integer, String > tMap = new TreeMap< Integer, String >();
// добавление элемента
tMap.put(556, “Monday”);
tMap.put(56, “Monday”);
tMap.put(85, “Tuesday”);
tMap.put(34, “Wednesday”);
tMap.put(815, “Saturday”);
tMap.put(724, “Sunday”);
// удаление элемента
tMap.remove(85);
// в TreeMap нету get по индексу и не наследует iterator
// поэтому передаем значения с помощью метода values
// конструктор другой коллекции, которую можно перебирать
ArrayList< String > tMapValues = new ArrayList< String >(tMap.values());
for(int i = 0; i < tMapValues.size(); i++) {
System.out.print(tMapValues.get(i) + " ");
}
System.out.println();
// или keySet если нужно перебирать ключи
ArrayList< Integer > tMapKeys = new ArrayList< Integer >(tMap.keySet());
for(int i = 0; i < tMapKeys.size(); i++) {
System.out.print(tMapKeys.get(i) + " ");
}
System.out.println();
// проверка на наличие элемента с таким ключем в списке
System.out.println(tMap.containsKey(56));
// проверка на наличие элемента с таким значением в списке
System.out.println(tMap.containsValue("Sunday"));
// для нахождения диапазонов
System.out.println(tMap.tailMap(556)); // выведет все элементы после 556
System.out.println(tMap.headMap(815)); // выведет все элементы до 815
// по результатам можно увидеть что элементы в порядке увеличения
}
}
Вывод:
LinkedHashMap
LinkedHashMap – элементы в отличие от hashmap содержат ссылку на предыдущий добавленный элементы и на следующий добавленный, как у LinkedList.
Проще говоря, это гибрид HashMap и LinkedList.
То есть лучше использовать когда элементы часто вставляются/удаляются.
Пример программы:
import java.util.*;
public class Map {
public static void main(String[] args) {
// создаем коллекцию
LinkedHashMap< Integer, String > lhMap = new LinkedHashMap< Integer, String >();
// добавление элемента
lhMap.put(556, “Monday”);
lhMap.put(556, “Monday”);
lhMap.put(85, “Tuesday”);
lhMap.put(34, “Wednesday”);
lhMap.put(815, “Saturday”);
lhMap.put(724, “Sunday”);
// удаление элемента
lhMap.remove(85);
//в linkedhashset нету get по индексу и не наследует iterator
//поэтому передаем значения с помощью метода values
//в конструктор другой коллекции, которую можно перебрать
ArrayList< String > lhMapValues = new ArrayList< String >(lhMap.values());
for(int i = 0; i < lhMapValues.size(); i++) {
System.out.print(lhMapValues.get(i)+" ");
}
System.out.println();
//или keySet если нужно перебрать ключи
ArrayList< Integer > lhMapKeys = new ArrayList< Integer >(lhMap.keySet());
for(int i = 0; i < lhMapKeys.size(); i++) {
System.out.print(lhMapKeys.get(i)+" ");
}
System.out.println();
// проверка на наличие элемента с таким ключем в списке
System.out.println(lhMap.containsKey(556));
// проверка на наличие элемента с таким значением в списке
System.out.println(lhMap.containsValue("Sunday"));
// По результатам можно видеть что элементы в порядке добавления
}
}
Благодаря классам реализующим Queue можно создавать массивы реализующие очередь.
Что такое очередь?
Очередь работает по принципу FIFO – first in first out (первый пришел – первым ушел). Представьте массив в который элементы можно добавлять только по очереди в конец, то есть после самого последнего элемента массива который был туда добавлен, а удалять элементы можно только по очереди начиная с самого первого элемента массива который мы туда добавили. То есть как видим первый вошедший в массив будет удален оттуда первым. Это и есть очередь.
Правда мы уже рассматривали LinkedList, который тоже реализует очередь (FIFO).
Помним, что если у LinkedList вызвать метод add, то элемент добавиться в конец LinkedList, если же вызвать просто remove без аргументов, то удалиться элемент, который был добавлен в очередь наиболее давно.
То есть, очевидно, что это реализация очереди.
У ArrayList, например, нельзя вызвать removeбез аргументов, поэтому ArrayList не является реализацией очереди.
У Queue же есть более интересные реализации очереди, например, приоритетная очередь – PriorityQueue.
При добавлении элемента в конец массива элементы в нем еще и сортируются по приоритету.
Приоритет задан по умолчанию у некоторых типов.
То есть если, например, массив PriorityQueue хранит Integer числа, то при добавлении числа в него будет происходить сортировка массива так, чтобы все элементы массива располагались в массиве от большего числа к меньшему.
При выборке же элемента из приоритетной очереди, будет происходить выборка элементов с того конца массива, где наименьшее число.
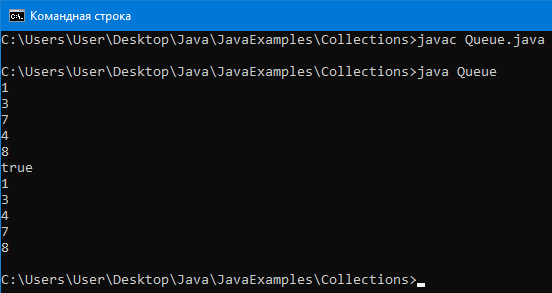
PriorityQueue
Пример программы:
import java.util.*;
public class Queue {
public static void main(String[] args) {
// Создаем приоритетную очередь, в которой
// будут храниться числа типа Integer
PriorityQueue< Integer > pQueue = new PriorityQueue< Integer >();
// добавление элемента
pQueue.add(4);
pQueue.add(3);
pQueue.add(7);
pQueue.add(1);
pQueue.add(8);
// В PriorityQueue нет метода get, поэтому сначала нужно
// преобразовать в массив, а потом извлекать,
// либо использовать итератор, который рассмотрим далее
Integer[] hSetArr = pQueue.toArray(new Integer[pQueue.size()]);
for (int i = 0; i < hSetArr.length; i++) {
System.out.println(hSetArr[i]);
}
// Проверка на наличие элемента в списке
System.out.println(pQueue.contains(3));
// Можно увидеть приоритет удаления (от меньшего числа к большему)
System.out.println(pQueue.remove());
System.out.println(pQueue.remove());
System.out.println(pQueue.remove());
System.out.println(pQueue.remove());
System.out.println(pQueue.remove());
// Как можно увидеть по результатам,
// удаляется от меньшего числа к большему.
}
}
Вывод:
Как можно увидеть по результатам, удаление происходит от меньшего числа к большему.
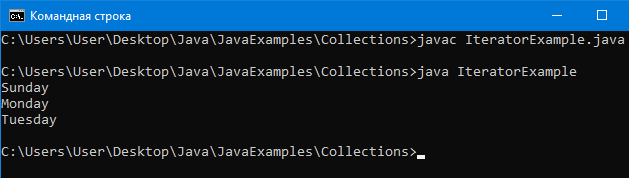
Благодаря Iteratorможно перебирать любую коллекциюне вникая в особенности какой-либо из них.
Пример программы:
import java.util.*;
@SuppressWarnings(“unchecked”)
public class IteratorExample {
public static void main(String[] args) {
ArrayList aList = new ArrayList();
aList.add(“Sunday”); // добавление элемента
aList.add(“Monday”);
aList.add(“Tuesday”);
// Доступ к каждому элементу через iterator
Iterator ir = aList.iterator();
while (ir.hasNext()) {
System.out.println(ir.next());
}
// То есть у любой коллекции есть iterator.
// С помощью которого можно пройтись
// по ее элементам.
}
}
Вывод:
Таким образом, у любой коллекции есть iterator, который позволяет перебирать её элементы.
Мы знаем, что у обычного Java массива есть строгая границаколичества элементов, которые могут в нем быть (эту границу мы задаем при инициализации вот так – int [] a = new int[5]).
Это называется статический массив.
Но часто может пригодиться динамический массив, то есть который может расширяться.
То есть у него нет фиксированно возможного количества элементов.
В Java в библиотеке Collections есть много разных динамических массивов каждый из которых нужен для разных задач и ситуаций.
То есть они не просто динамические массивы, а еще и имеют разную структуру и применение.
Поэтому в Java корректно называть их не просто “динамическими массивами”, а коллекциями.
Есть четыре основных вида коллекций List, Queue, Set и Map.
Каждая из коллекций имеет свои подвиды, которые мы будем разбирать.
Важно упомянуть что List, Queue, Set и Map это интерфейсы которые имеют разные реализации (подвиды).
ArrayList
Для начала разберем реализации List.
Благодаря классам реализующим List можно создать динамически изменяющийся массив.
Первый подвид List, который мы рассмотрим это ArrayList.
ArrayList – лучше использовать когда часто нужен доступ по индексу
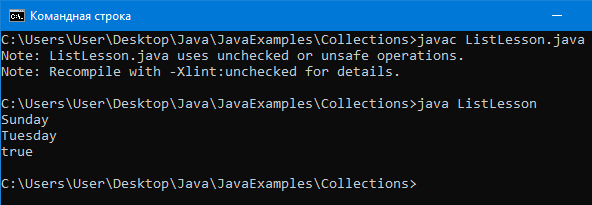
Пример программы:
import java.util.*;
public class ListLesson {
public static void main(String[] args) {
//Создаем список.
//Как видим никакого размера не указываем
ArrayList aList = new ArrayList();
// добавление элемента
aList.add(“Sunday”);
aList.add(“Monday”);
aList.add(“Tuesday”);
// удаление элемента
aList.remove(“Monday”);
//Доступ к каждому элементу с помощью get.
//метод get для доступа к элементам по индексу
for(int i = 0; i< aList.size(); i++) {
System.out.println(aList.get(i));
}
// проверка на наличие элемента в списке
System.out.println(aList.contains("Tuesday"));
}
}
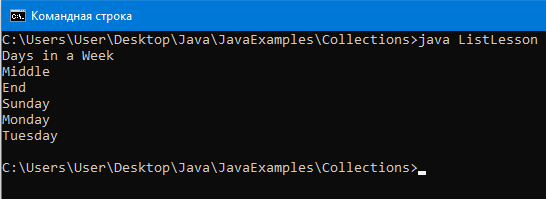
Вывод:
LinkedList
LinkedList – лучше использовать когда часто производиться вставка/удаление из массива, занимает больше памяти чем ArrayList.
Пример программы:
import java.util.*;
public class ListLesson {
public static void main(String[] args) {
// Создать новый объект LinkedList
LinkedList llist = new LinkedList();
// Добавление элементов в связанный список
// тем же методом что и у ArrayList.
llist.add(“Days in a Week”); // добавить
// Добавить в произвольное место связанного списка
llist.add(1, “Middle”);
llist.add(2, “End”);
// Удаление элемента
llist.remove(“End”);
// Если не вписать аргумент, то удалится элемент,
// который был добавлен в массив наиболее давно.
llist.remove();
// Доступ к каждому элементу с помощью get
for (int i = 0; i < llist.size(); i++) {
System.out.println(llist.get(i));
}
// проверка на наличие элемента в списке
System.out.println(llist.contains("Tuesday"));
}
}
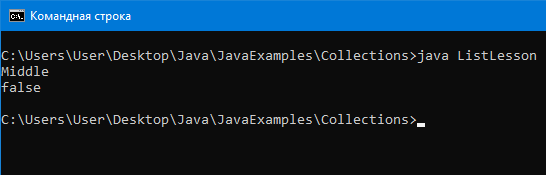
Вывод:
Из реализаций List есть еще Vector – это как ArrayList, только синхронизирован(для работы с потоками, их будем проходить потом).
Конвертация коллекции из одного типа в другой.
Можно при создании коллекции поместить в нее элементы из другой ранее созданной коллекции.
При этом эта другая коллекция может быть другого типа по отношению к создаваемой. То есть фактически это значит, что возможно менять тип коллекции.
Пример программы:
import java.util.*;
class ListLesson {
public static void main(String[] args) {
// создаем список
ArrayList aList = new ArrayList();
aList.add(“Sunday”);
aList.add(“Monday”);
aList.add(“Tuesday”);
// Создать новый объект LinkedList
LinkedList lList = new LinkedList();
lList.add(“Days in a Week”);
lList.add(1, “Middle”);
lList.add(2, “End”);
//Можно создать коллекцию с элементами другой коллекции
//другого типа. Можно сказать, что снизу мы поменяли тип
//ранее созданной коллекции lList с LinkedList на ArrayList.
ArrayList< String > LinkedToArray = new ArrayList<>(lList);
LinkedList< String > ArrayToLinked = new LinkedList<>(aList);
//Выведем на консоль коллекции
for(int i = 0; i < LinkedToArray.size(); i++) {
System.out.println(LinkedToArray.get(i));
}
for(int i = 0; i< ArrayToLinked.size(); i++) {
System.out.println(ArrayToLinked.get(i));
}
//также можно задать значение
//начального размера внутреннего массива
ArrayList< String > list2 = new ArrayList<>(10000);
}
}
Внимание! Перед прохождением данного урока сначала необходимо пройти следующий раздел, а потом обязательно возвращайтесь сюда, данный урок довольно важен.
Если у любого объекта вызвать метод hashCode, то его реализация по умолчанию вернет нам число.
Это случайное уникальное число, которое генерируется этим методом по умолчанию.
Переопределять его нужно если мы собираемся запихивать в HashSet или HashMapне простые элементы типа char, int, String и т.д., а объекты.
То есть, например, так – set.add(new MyClass(1, 34));.
Вот например мы только что записали в set объект new MyClass(1, 34) и у нас в классе MyClass пока не переопределен hashCode и если мы теперь запишем в этот же set такой же объект new MyClass(1, 34) еще раз вот так – set.add(new MyClass(1, 34));, то в set уже будет ДВА элемента.
А это не должно быть так! Так как мы помним, что ни в HashSet, ни в HashMap одинаковые ключи храниться не должны.
Почему же если мы записываем в hashset идентичные объекты, как ключи, то hashset рассматривает их как разные ключи?
Реализация метода hashCode по умолчанию генерирует разные ключи всем объектам ДАЖЕ ЕСЛИ ОНИ ИДЕНТИЧНЫпо своему содержанию.
То есть если мы создаем объект new MyClass(1, 34) в первый раз, то у него будет свой hashCode, когда мы создаем new MyClass(1, 34) второй раз, у него уже будет другой hashCode.
Каждый объект имеет свой hashCode. И hashset добавляет объекты в себя по этому hashCode.
Если hashCode у добавляемых объектов разный, значит эти объекты с наибольшей вероятностью попадут в разные linkedlist-ы в 16 linkedlist-ах, если же они одинаковые, то объекты будут попадать в один и тот же linkedlist.
Как же нам переопределить hashCode, чтобы идентичные объекты всегда записывались в один и тот же linkedlist?
Нам нужно переопределить hashCode так, чтобы он возвращал данные объекта представленные одним восьмибитным числом.
То есть все значения полей объекта нам нужно каким-то образом скомпановать в одно восьмибитное число, которое будет возвращать hashCode.
И теперь hashCode всех идентичных объектов, например, new MyClass(1, 34) всегда будет возвращать один и тот же hashCode, так как он является скомпонованными полями объекта, а поля у идентичных объектов new MyClass(1, 34) одинаковые – 1 и 34.
Но на этом еще не всё. Если объекты одинаковы по hashCode, это только значит, что они попадут в один и тот же самый linkedlist, это еще не обязательно значит, что они одинаковы полностью.
HashSet еще будет сравнивать добавляемый в него объект со всеми уже присутствующими в hashset элементами методом equals и если он НЕ найдет там методом equals идентичный элемент, но при этом объект с таким hashCode уже там присутствует, то в hashset всё равно добавиться этот добавляемый объект и в итоге в нем будет два элемента с одинаковыми hashCode.
Поэтому, чтобы в HashSet не было идентичных объектов, обязательно вместе с hashCode должен быть переопределен и equals.
Переопределение HashCode
Пример программы:
import java.util.*;
class MyClass implements Cloneable {
int myA;
SomeClass myB;
MyClass(int myA, SomeClass myB){
this.myA = myA;
this.myB = myB;
}
// hashCode – данные класса представлены одним восьмибитным числом.
// По умолчанию, если не переопределять, это случайное уникальное число.
@Override
public int hashCode() {
System.out.println(“HashCode is called: ” + this);
// Это стандартное переопределение. Не заморачивайтесь почему 31,
// почему умножение. нам лишь важно в result
// добавить все поля класса, так как result это и есть
// это самое восьмибитное число, состоящее из полей класса.
final int prime = 31;
int result = 1;
// Числовые переменные просто добавляем.
result = prime * result + myA;
// У полей объектов вызываем hashCode.
// Метод hashCode в классе этих объектов
// тоже должен быть определен таким же образом.
result = prime * result + myB.hashCode();
return result;
}
// equals обязательно тоже переопределяем, как уже было сказано
@Override
public boolean equals(Object obj) {
System.out.println(“Equals is called:” + this + ” : ” + obj);
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyClass other = (MyClass) obj;
if (myA != other.myA)
return false;
if (!myB.equals(other.myB))
return false;
return true;
}
@Override
public String toString() {
return “MyClass{” + “myA=” + myA + “, myB='” + myB + ‘\” + ‘}’;
}
@Override
public SomeClass clone() throws CloneNotSupportedException {
Object obj = super.clone();
SomeClass someClass = (SomeClass) obj;
return someClass;
}
}
class SomeClass implements Cloneable {
int someVar;
SomeClass(int someVar){
this.someVar = someVar;
}
// Здесь тоже переопределены hashCode и equals
@Override
public int hashCode() {
System.out.println(“HashCode is called:” + this);
final int prime = 31;
int result = 1;
result = prime * result + someVar;
return result;
}
@Override
public boolean equals(Object obj) {
System.out.println(“Equals is called:” + this + ” : ” + obj);
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
SomeClass other = (SomeClass) obj;
if (someVar != other.someVar)
return false;
return true;
}
@Override
public SomeClass clone() throws CloneNotSupportedException {
Object obj = super.clone();
SomeClass someclass = (SomeClass)obj;
return someclass;
}
public String toString(){
return “SomeClass{” + “someVar=” + someVar + ‘}’;
}
}
public class hashCodeLesson {
public static void main(String[] args)
throws CloneNotSupportedException {
Set< MyClass > set = new HashSet<>();
set.add(new MyClass(1, new SomeClass(34)));
set.add(new MyClass(1, new SomeClass(36)));
set.add(new MyClass(1, new SomeClass(34)));
set.add(new MyClass(2, new SomeClass(26)));
set.add(new MyClass(3, new SomeClass(75)));
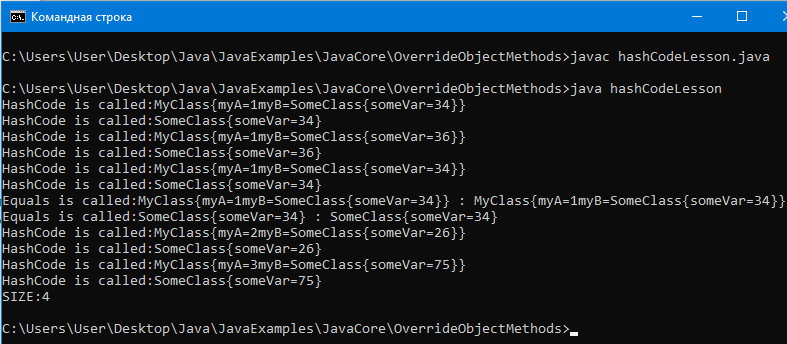
System.out.println(“SIZE:” + set.size());
// По результатам можно увидеть, что размер коллекции 4,
// так как для 1 и 3 элементов хеш-коды одинаковые,
// и equals сравнил поля, которые оказались одинаковыми.
// Если бы hashCode не был переопределен, элементов было бы 5.
}
}
Вывод:
Последовательность добавления элементов в HashSet
Также стоит упомянуть некоторые детали последовательности добавления элементов в HashSet.
При добавлении ключа в HashSet и расчета его hashCode происходит сравнение этого hashCode с hashCode каждого элемента в HashSet, и если hashCode очередного добавляемого объекта отличается от всех остальных уже присутствующих в коллекции, то ключ добавляется СРАЗУ, без сравнения по equals.
Если же такой же hashCode нашелся, то происходит сравнение по equals, и если этим методом не найдет такого же элемента, то произойдет добавление.
В этом уроке был приведен пример стандартного переопределения hashCode.
Таким вот образом его нужно переопределять почти всегда когда вы работаете с hash коллекциями.
equalsпо умолчанию проверяет только то, ссылаются ли две ссылки на один и тот же объект.
Если нам нужно проверить не только это, а является ли содержимое одного объекта одинаковым с другим объектом, то его нужно переопределять.
Переопределение Equals
Пример программы:
mport java.util.*;
class MyClass implements Cloneable {
int myA;
SomeClass myB;
MyClass(int myA, SomeClass myB){
this.myA = myA;
this.myB = myB;
}
// Переопределим equals чтоб он сравнивал не только то
// ссылаются ли ссылки на один и тот же объект
@Override
// Как уже говорили все классы наследуют от Object
// поэтому можно сделать так – equals(Object obj)
// И теперь в equals параметром можно передавать
// объекты любого типа – MyClass или SomeClass.
public boolean equals(Object obj) {
System.out.println(“Equals is called:” + this + “:” + obj);
//проверка ссылки
if (this == obj)
return true;
//проверка на пуст ли передаваемый объект
if (obj == null)
return false;
//getClass возвращает название класса
//переданного сюда параметром.
//Проверка объектов на принадлежность одному классу
if (getClass() != obj.getClass())
return false;
//сравнение полей
MyClass other = (MyClass) obj;
if (myA != other.myA)
return false;
//для ссылочных полей сравнение по “!=” не подходит
//нужно использовать equals и конечно в классах этих
//ссылочных полей тоже должен быть определен
//equals. в классе SomeClass ниже можно увидеть
//пример такого equals.
//Теперь мы его используем с строке кода ниже
if (!myB.equals(other.myB))
return false;
return true;
}
@Override
public String toString(){
return “MyClass{” + “myA=” + myA + “, myB=” + myB + ‘}’;
}
@Override
public MyClass clone()
throws CloneNotSupportedException{
Object obj = super.clone();
MyClass myClass = (MyClass)obj;
return myClass;
}
}
class SomeClass implements Cloneable {
int someVar;
SomeClass(int someVar){
this.someVar = someVar;
}
// Тоже переопределяем equals
@Override
public boolean equals(Object obj){
System.out.println(“Equals is called:”
+ this + ” : ” + obj);
// проверка ссылки
if (this == obj)
return true;
// проверка на пуст ли передаваемый объект
if (obj == null)
return false;
// Проверяем объекты на принадлежность одному классу
if (getClass() != obj.getClass())
return false;
// сравнение полей
SomeClass other = (SomeClass) obj;
if (someVar != other.someVar)
return false;
return true;
}
@Override
public SomeClass clone()
throws CloneNotSupportedException{
Object obj = super.clone();
SomeClass someclass = (SomeClass)obj;
return someclass;
}
@Override
public String toString(){
return “SomeClass{” + “someVar=” + someVar + ‘}’;
}
}
public class EqualsLesson {
public static void main(String[] args)
throws CloneNotSupportedException{
SomeClass someClass = new SomeClass(10);
MyClass myClass = new MyClass(10, someClass);
SomeClass someClass1 = new SomeClass(10);
MyClass myClass1 = new MyClass(10, someClass1);
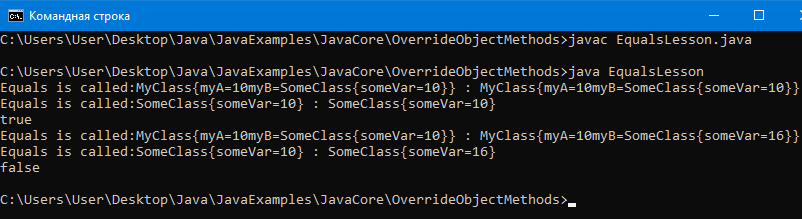
System.out.println(myClass.equals(myClass1));
// В консоли можно увидеть что equals включит true.
// Это значит что myClass полностью
// равен по значениям myClass1
// Давайте для дополнительной проверки изменим
// какое-то поле myClass1
someClass1.someVar = 16;
// проверим
System.out.println(myClass.equals(myClass1));
// уже не полностью равны
}
}
Второй метод Object это метод clone, который клонирует объект.
Происходит копирование всех полей клонируемого объекта в новый объект-клон.
Но по умолчанию методом clone в новый объект копируются только примитивные поля объекта, а ссылочные нет, поэтому clone тоже нужно переопределять.
В Java управление объектами осуществляется с помощью ссылочных переменных, инет операторадля фактического копирования объекта, поэтому и существует clone.
Переопределение Clone
Напрямую вызвать clone у какого либо объекта в main нельзя, так как метод clone внутри Object объявлен protected.
Поэтому для того чтобы вызвать clone у какого либо объекта еговсегда нужно переопределять.
То есть имеется ввиду, что даже чтобы использовать стандартную реализацию clone, которая копирует только примитивные поля всё равно нужно сделать минимальное переопределение clone, как это сделано в классе SomeClass ниже.
Создадим два класса, в которых будем переопределять clone.
Все классы, которые переопределяют clone должны реализовывать интерфейсCloneable. То есть видим ниже в примере программы implements Cloneable
Пример программы:
import java.util.*;
class SomeClass implements Cloneable {
int someVar;
SomeClass(int someVar){
this.someVar = someVar;
}
//неопределим clone для SomeClass
@Override
public SomeClass clone() throws CloneNotSupportedException{
//Слово super это супер класс то есть класс
// от которого наследует текущий класс
//Текущий класс наследует от Object.
//Слово super это ссылка на родительский класс Object.
//super.clone() – через супер класс клонируем
//текущий объект. Как уже было сказано
//у нового объекта copy копируются только примитивные
//поля объекта SomeClass. В нашем случае someVar.
Object obj = super.clone();
//Теперь новый объект clone SomeClass пока типа Object
//нам нужно привести его к SomeClass.
SomeClass someclass = (SomeClass)obj;
//Мы можем это сделать так как
//SomeClass наследует от Object.
//class SomeClass – extends Object;
//А значит имеет в своем составе
//все поля и методы SomeClass и в него были
//скопированы все НЕ ссылочные поля то есть someVar
//Ссылочных полей здесь нет
//поэтому такого переопределения достаточно
return someclass;//возвращаем клон
}
public String toString(){
return “SomeClass{“+ “someVar=” + someVar + ‘}’;
}
}
class MyClass implements Cloneable {
int myA;
SomeClass myB;
MyClass(int myA, SomeClass myB){
this.myA = myA;
this.myB = myB;
}
//clone должен копировать как простые
//так и ссылочные типы объекта
@Override
public MyClass clone() throws CloneNotSupportedException{
//Здесь для клонирования не ссылочных полей
//объекта MyClass производится те же действия
//что и в предыдущем классе.
Object obj = super.clone();
MyClass myclass = (MyClass)obj;
//В этом классе уже есть ссылочное поле это myB,
//его нужно клонировать. Для этого
//мы должны вызвать метод clone() из переопределения
//SomeClass. Он клонирует все примитивные поля
//из объекта myB, который является объектом
//SomeClass, который мы сейчас клонировали.
//И возвращает myclass, который является клоном.
myclass.myB = myB.clone();
return myclass;
}
public String toString(){
return “MyClass{” + “myA=” + myA + “, myB=” + myB + ‘}’;
}
}
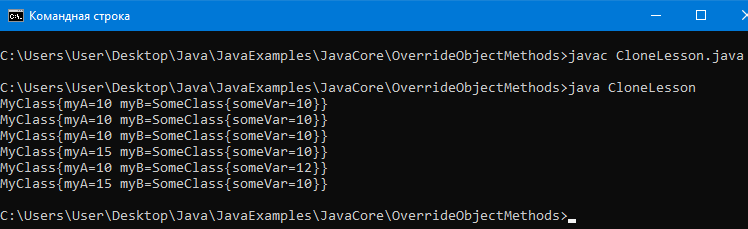
public class CloneLesson {
public static void main(String[] args)
throws CloneNotSupportedException {
//Создаем объект SomeClass и объект MyClass
SomeClass someClass = new SomeClass(10);
MyClass myclass = new MyClass(10,someClass);
//клонируем myclass.
MyClass myclass1 = myclass.clone();
//Выведем на консоль поля клонируемого
//объекта и клона.
System.out.println(myclass);
//Как можно увидеть по результатам все поля
//примитивного типа и все типы ссылочные
//очень someClass из myclass.
System.out.println(myclass1);
//Теперь самое главное. Нужно точно убедиться
//что объекты myclass и myclass1 не ссылаются на один
//и тот же объект и тогда точно можно будет сказать
//что клонирование прошло успешно. Для этого создадим
//новый объект someClass и присвоим его полю myB
//объекта myclass1. Если клонирование прошло успешно
//то объект someClass никак не должен измениться
//в объекте myclass и убедимся что это не произошло.
//Если клонирование прошло успешно то объекты
//myclass и myclass1 будут разные, что они и отдельны.
someClass = new SomeClass(12);
myclass1.myB = someClass;
System.out.println(myclass);
System.out.println(myclass1);
//Теперь изменим ссылочное поле в myclass1
//и убедимся что это не изменило myclass
myclass1.myB.someVar = 12;
System.out.println(myclass);
System.out.println(myclass1);
}
}